Java 并发知识
(本书还在编写中,如果有任何的疑问或建议可以邮件反馈)
并发(Concurrency)有两层含义:
- 宏观层面,并发意味着有事件“同时”发生1,如:网络里的多台机器同时发请求;同一台机器上的多个进程;同一个进程里的多个线程等。
- 微观层面,并发意味着来自各方的事件会被拆解成最小的执行单元(如请求、操作、指令等),它们会被乱序或部分有序地执行,我们希望不影响最终的结果2
在 Java 里,并发的宏观表现就是多线程3,微观上直接表现的是字节码,除此之外,我们还要站在 JVM 的角度,了解 CPU 指令、内存等因素对字节码执行顺序的影响。
为什么要用并发的方式编程?是因为我们想利用多线程提高程序的执行效率,但随之而来的就是种种正确性问题,并发编程中,我们会在正确性与性能间不断权衡。例如为了提高性能,我们只想在必要的地方加锁(细粒度),但这样可能很难保证程序的正确性;而如果加了粗粒度的锁(最极端就是全局加锁,等于单线程运行),正确性容易保证,但性能差。
并发产生的正确性问题通常也叫线程安全问题,本书的第一部分我们就会讨论线程安全相关的话题,了解它产生的原因,如何避免等。而为了充分利用多线程的优势,我们需要了解锁的性能,线程切换的损耗等知识,提高程序的性能。
不过在日常的编码中,我们不会经常性地直接使用底层的能力,而是用一些已经封装好的工具,如 JUC 库等,所以我们还会谈一谈其中一些库的使用和原理。
本书一方面是个人学习的记录,一方面是尝试对自身知识的提炼。讲述方式会自底向上,内容偏底层原理的理解。希望你在阅读的你有所帮助。
另外,本人水平有限,有理解不正确的地方,欢迎批评指正,我相信相互交流才能让我们彼此有更大的提升。
https://web.mit.edu/6.005/www/fa14/classes/17-concurrency/#concurrency 2: https://en.wikipedia.org/wiki/Concurrency_(computer_science) 3: 在一些支持协程的语言(如 Go)中,单线程也可以产生并发,关键是微观上是否有乱序
理想的并发世界
并发问题,或者说线程安全问题的根本原因是我们对编写代码的运行逻辑有某种预期,而这种预期 JVM 或机器无法满足。那么我们会有什么预期呢?
单线程的执行顺序
我们对代码运行逻辑的预期主要有两个:
- 写在代码里的操作/语句,按先后顺序执行
- 前面操作的结果对后面的操作可见
例如 Java 代码:
// 初始条件 x = 0; y = 0;
1. x = 1;
2. if (x > 0)
3. y = 2;
我们很自然地预期执行的顺序是 1 > 2 > 3,写在前面的先执行。同时在 #1 执行后,我们预期 #2 就能看到结果,于是 #2 的 if 判断结果为 true。
这是单线程的情况,我们预期代码的执行顺序就是代码撰写的顺序。那么多线程下呢?我们会有什么预期?
Sequential Consistency
在多线程语境下,什么执行顺序才是合理的预期呢?Leslie Lamport 提出了 Sequential Consistency (顺序一致性)来更精确地定义我们的合理预期:
... the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.1
考虑 CPU 多个核的执行顺序,多核的执行结果,相当于把每个核要执行的操作汇总排个序,在这个顺序里,要求每个核的操作依旧保持在单核内的相对顺序。例如,下图中有两个线程 A 和 B,它们各自要执行两个操作,则符合 Sequential Consistency 的顺序如下所示:

可以看到,这些顺序里,A1 永远在 A2 之前,B1 永远在 B2 之前,而 A 和
B 的相对顺序是没有指定的。换句话说,我们会希望,在并发的情况下,每个线程自己操作的执行顺序,在汇总的全局排序下依旧保持不变(代码撰写的顺序)。
可以理解为 Sequential Consistency 就是将多个线程要执行的代码交错(interleave)排成一个新的序列。
注意的是,Sequential Consistency 其实有两很强的隐藏假设:
- 每一个操作都要是原子的,操作在执行过程中不能被打断。
- 操作对下一个操作可见2。如
r1 = B执行结束后,后续操作读取r1时要读到B这个值。
这个假设很符合直觉,后面我们会说明,其实底层却很难做到。
线程同步
Sequential Consistency 很好地描述了我们对多线程代码执行逻辑的合理预期,但 Sequential Consistency 对线程之间的操作先后并没有规定。如果我们希望先执行线程A 的某些操作,之后才允许执行线程 B 的某些操作(即线程同步)要怎么做呢?我们会看到,如果底层能满足 Sequential Consistency 的约定,则我们可以通过一些算法自己来实现同步。
考虑临界区(critical section)问题:希望其中的代码(一般包含多个操作)“同时”只有一个线程在执行。从微观层面,即希望这些代码所代表的操作整体上“原子地”执行,这些操作进行时不被其它线程的操作插队。下面是 Dekker 算法(该算法不理解也没关系,实际上用不到):
----------- Thread A --------+--------- Thread B -----------
1. a = 1; | 1. b = 1;
2. turn = 1; | 2. turn = 2;
3. if (b == 1) | 3. if (a == 1)
4. if (turn == 1) | 4. if (turn == 2)
5. goto #3 | 5. goto #3
6. <critical section> | 6. <critical section>
7. a = 0 | 7. b = 0
我们希望“同一时刻”,只有一个线程进入临界区(#6),所以我们在 #6 之前写了很多同步的逻辑,如果程序执行能满足 Sequential Consistency,那么上面的算法就能满足,在任意时刻,线程 A/B 只有一个能进入临界区,执行 #6 中的代码(实际可能有多行)。下面会尝试证明(不理解也不影响阅读)。
不考虑一方先执行到 #7 的情况,因为此时无冲突。假设线程 A 先进入临界区,则 A3(线程 A 第 3 行)和 A4 条件必有一个不成立。先考虑 A3 不成立,则可以确定 A3 > B1(A3 排序在 B1 之前),由于底层满足 Sequential Consistency,则有 A1 > A3,
B1 > B2 > B3,可以确认 A1 > A2 > B2 > B3,则此时 B3, B4肯定成立,线程 B 进入不了临界区 B6;考虑 A4 不成立,由于考虑的是 A 先进入临界区,则有 A4 > B4,由于 A4 不成立,则有 B1 > A3保证 A3成立,同时 B2 > A2使 A4 不成立,则推出A1 | B2 > A2 > A4 > B4,可以确定B3 B4 都是成立的,线程B 无法进入临界区。同理,任意一方的 #3 或#4条件不满足,先进入了临界区,则另一方肯定进不了临界区。
我们看到,如果系统提供了 Sequential Consistency,则我们可以通过一些(不容易想到的)算法来达到线程间的同步,即人为地对多个线程间的相对执行顺序做约束。
只要看上去如此
事实上,机器真的会按上面所说的顺序执行代码吗?或者说,我们关心吗?
这也是理解并发编程的一个思维转变,我们其实不关心机器到底是如何执行的,我们只关心最终的结果是否符合预期。我们需要和机器有个约定,这样当结果不符合预期时,我们好分辩是代码写错了,还是机器执行错了。
这样能允许底层实现做一些优化,例如,如果线程之间没有任何的共享变量,机器可以并行地执行这些线程,最终的结果仍然满足 Sequential Consistency。
小结
本章中,我们主要探讨了对于多线程的代码在运行时,什么才是合理的预期结果。
Sequential Consistency 是一个符合直觉的合理预期,它没有对线程间的相对顺序做任何约束,不过我们依旧可以用一些算法来实现线程间的同步。
下一章中,我们会看到 Sequential Consistency 模型的约束太强了,编译器、CPU、内存几乎没办法做任何优化,也因此目前没有任何 CPU、JVM 能实现 Sequential Consistency。
但至少,我们知道了理想的世界应该是什么样的。
https://en.wikipedia.org/wiki/Sequential_consistency
维基百科 里说:Sequential Consistency 中一个写入一个变量不需要被“立即”看到。与我们文中说的“操作对下一个操作可见”似乎有冲突。我翻了很多资料,最终的理解是:“写入不需要被立即看到”的语境是排序前,如果有一写两读,W(2), R1, R2,最终如果排序成 R1, W(2), R2 则代表了 W(2) 被延时感知了。但是排序后的操作仍旧必须对下一个操作可见。
残酷的现实
我们常说并发问题的根源是原子性(Atomicity)、可见性(Visibility)与有序性 (Ordering)。它们是祭品,是我们换取极致性能的代价。
本章我们来看看这三个性质是什么,以及破坏它们的缘由。
缓存层次结构
在了解三个性质之前,我们先了解一下 CPU 的缓存结构,它对这些性质有很大的影响。
当前 CPU 性能强劲,程序的主要的瓶颈不在计算,而在数据读写。根据 Latency Numbers Every Programmer Should Know 里的数据,2020 年,访问 L1 缓存需要 1ns,而访问内存/主存则需要 100ns。因此不管是硬件还是软件的优化,都在尝试提升缓存的命中率。而破坏原子性、可见性、有序性,很大程度上也是为了充分利用缓存。
Core i7 缓存结构
我们来看看 Core i7 的经典三层缓存结构1(有大概印象就行,不需要深入理解),如下图:

核内独占 L1, L2 缓存,核间共享 L3 缓存。其中 L1 分为指令高速缓存(i-cache)和数据高速缓存(d-cache)。
在 CPU 指令需要读取内存时,会先尝试从 L1 缓存中读取,如果发现缓存中没有(称作 cache miss),则开始从 L2 中读取,依此类推,最终会从内存中读取数据。我们上面说过,缓存的访问速度与内存的访问速度天差地别,因此很多时候,无论是编译器还是 CPU 都会尽量让运行的代码能充分利用缓存。
在 CPU 需要写入内存时,有两种策略:直写(write-through)和回写(write-back)。直写会要求把写入的值一路直接写回内存,属于简单粗爆型;而回写则是先写回缓存,等待某个合适的时机,再将缓存中的所有修改一次性写回内存,性能上会更好。
(要注意的是,现代 CPU 有很多优化,这里的讨论只关心缓存的理论模型,不关心实现细节)
缓存友好的代码
考虑对一个二维数组的遍历,有两种写法:
for (int i=0; i<rows; i++) { | for (int j=0; i<cols; j++) {
for(int j=0; j<cols; j++) { | for(int i=0; j<rows; i++) {
array[i][j] += 42; | array[i][j] += 42;
} | }
} | }
哪一种效率更高呢?它们的区别仅仅只在于优先遍历行(左)还是优先遍历列(右)。事实上左边代码的效率远高于右边的代码,这是因为通常行的数据在内存里是连续排布的,按行遍历时,该行下一列元素的缓存命中率会比按列遍历时,该列一下个元素的命中率高很多,这能极大提高程序的效率(可能会高几十倍)。
当然,我们写代码的时候不会也不应该时刻考虑这么细节的优化,大部分情况下这是编译器和 CPU 要考虑的事。这就引出了影响并发问题的几个关键因素。
原子性
原子在物理上是不可分割的粒子2,在编程的语境中,原子性的含义是:
If an action is (or a set of actions are) atomic, its result must be seen to happen "all at once", or indivisibly.
体现在一个或多个操作作为一个整体,执行的结果看起来是“一起”发生的,不被其它的操作打断或影响。
原子性的粒度
你可能已经知道,Java 中的 ++ 操作不是原子的,因为它对应的字节码等价于下面伪代码:
Initial: x = 0;
----------- Thread A --------+--------- Thread B -----------
x++; | x++;
1. reg0 = value_of_X |
2. reg0 = reg0 + 1 |
| 1. reg0 = value_of_X
| 2. reg0 = reg0 + 1
| 3. value_of_X = reg0
3. value_of_X = reg0 |
Result: x = 1 v x = 1
JVM 并不保证这些 3 个字节码作为一个整体是原子的,于是如上述代码所示,在最终结束后,两个线程都得到 x=1 的结果,但预期至少有一个线程应该得到 x = 2 的结果。
这个例子中,我们隐含假设了字节码的执行是原子的,在这种情况下,由多条字段码组成的 ++ 操作不是原子的。这个结论在各个粒度下都适用:即使 CPU 指令都是原子的,由它组成的字节码也不一定是原子的;即使字节码都是原子的,由它组成的 Java 操作也不一定是原子的;即使 Java 操作是原子的,由它组成的 Java 函数也不一定是原子的。
上层的原子能力依赖下层
反过来,如果上层的某些操作是原子的,那么它一定需要更底层的原子能力支持。
例如之前章节中提到的 Dekker 算法,它能够从软件层面实现互斥锁,但是它依赖变量读写操作的原子性。
Java 提供了内置锁(Intrinsic Lock/Monitor Lock) 等语义帮助我们方便地实现多个 Java 操作整体的原子性(可以是一个函数,可以是几行语句),但我们要意识到Java 在实现这些机制时依赖了操作系统提供的原子能力。
通常操作系统会提供一些原子能力,如 Linux 提供了互斥锁(Mutex)、信号量 (Semaphore)和自旋锁(SpinLock)等锁的语义。而操作系统又依赖一些 CPU 的指令来实现,如 x86 提供了 CMPXCHG 指令3 和 LOCK 等锁的语义。
至于 CPU 的锁是如何实现的,就超出了我的知识范围了。
为什么不默认原子性?
Java 语言规范规定了读写一个变量是原子操作(除了 long 和 double 型变量),而
long 和 double 型变量只有在声明为 volatile 时才是原子的。为什么不让所有操作都变成原子的呢?
我个人理解有两点(很少看到相关讨论):
- 原子性通常意味着独占某些资源,如 CPU 数据总线,使得底层没有优化空间
- 原子性如果缺少了可见性,通常就没太大用处(如 Sequential Consistency 同时要求原子性与可见性),而可见性的实现代价太高了,不适合作为默认选项。
可见性
可见性问题可以简单表述为,线程 A 写入某个变量后,线程 B 读取,读到的值会是最新的值吗?前文提到的 Sequential Consistency 是有这个要求的,JVM 能提供这个保证吗?
答案是不行。考虑下面的示例:
public class Shared {
private int count = 0;
public void write() {
count = 1;
}
public void read() {
System.out.println(count); // ①
}
}
如果线程 1 先调用 write 方法,线程 2 再调用 read 方法,此时可能发生如下情形:

虽然 CPU 1 写入操作成功,但写入的值并没有被 CPU 2 读到4。
你可能有疑问,我们在编写单线程的程序时,好像也没有管过可见性问题啊?这是因为操作系统给我们提供了保证5:
- 操作系统会保证单线程的代码在一个核上运行,读写肯定都是这个核的缓存,没有可见性问题。
- 如果线程发生了切换,线程在另一个核上恢复运行,那么操作系统需要做状态的保存和还原,保证新核上的缓存反映了之前的修改。
为什么不保证所有操作的可见性?原因可能已经很明显了,就是性能,读写内存对 CPU 来说实在是太慢了,每个读写操作都同步会极大降低性能6。
有序性
如果说可见性是因为缓存问题客观上被破坏的,那么有序性就是一个主观的破坏行为,主观上进行重排序来提高程序的性能。程序的重排序一般有两方面:编译器在编译时会对代码进行重排序;CPU 在执行指令时可能会乱序执行,除此之外Java 使用的 JIT 也对执行的指令有重排序。而这样做的目的,都是为了提高性能。下面举几个重排序的例子7:

- 这个例子很好理解,省去了无用的赋值。
- 这个例子是编译器很重要的一个优化,与其在循环内不断更新内存变量
z,我们用寄存器r1来临时存储计算结果,循环结束后再更新到内存z中。 - 这个例子重新排序了我们的赋值语句,可能上面的代码刚刚访过变量
z,因此将对z的赋值提前可以充分利用已有的缓存。 - 这个例子和我们前面小节说的,将一个按列遍历的逻辑替换成按行遍历的逻辑,能提高缓存的命中率。
在单线程的程序中,编译器、CPU 总是在做着这些重排序,并且最终的结果“看上去”和不进行重排序没有区别,为什么到了多线程就到处是坑呢?
这是因为单线程程序的预期运行顺序和代码的编写顺序一样,编译器预先知道了各个操作的依赖关系,因此可以在不破坏依赖关系的前提下进行重排序,而在多线程的语境下,只看代码,编译器并没有办法推断出代码的依赖关系,无法知道一个线程里的 write 操作是不是一定要在另一个线程的 read操作前执行,无法合理地做出推断。那要怎么办呢?
编程语言会提供一些语义(如 Java 中的 synchronized volatile 等),程序员需要在编代码时,显示地指定线程间的执行顺序依赖,这样编译器会保证在重排序时不破坏这种关系,反之,如果没有指定,编译器就不做任何保证。
小结
尽管前面章节中我们定义了 Sequential Consistency,认为在多线程编码中它是符合常理的预期,但现实世界中,为了程序运行的效率,这些预期无法被满足。
我们先学习了 CPU 的缓存层级结构,了解了缓存的性能优势。之后介绍了原子性、可见性、有序性这三个引发并发问题的根源。编译器、CPU 打破这三个保证,是为了换取更高的性能,并且在单线程情况下,也不会对程序的正确性产生影响,是很有价值的权衡。
但是在多线程的语境下,程序的正确性就会受到冲击,因此需要有新的机制来修补这些问题,下一章我们会介绍 Java 的内存模型。
图来源于《深入理解计算机系统》
虽然可能大家都知道,原子也是可分的,但在长时间内,原子是被认为不可分的
CMPXCHG 指令代表的是 CAS(compare and swap) 机制,Java 的 AtomicInteger 和 ReentrantLock 等的实现依赖了 CAS 机制,后续章节会介绍。
注意这个示例是理论模型上会发生的,实际上现代的一些 CPU 在缓存之间有诸如 MESI 的同步机制,能保证写入缓存的数据可以被其它核读取,这叫作缓存一致性(cache-coherency),可以参考这篇文章
参考这个回答 https://stackoverflow.com/a/59159989/826907
如上面的注脚提到的,CPU 层面也在尝试优化缓存间的数据同步,如 MESI 协议
例子取自 Herb Sutter 的演讲,PPT 链接
Happens Before
前文描述了 Sequential Consistency,它是并发下我们对程序运行顺序的合理预期,也描述了底层结构为了提升效率,打破了原子性、可见性、顺序性。而之所以在单线程下没有这些问题,在并发下就会有线程安全的问题,是因为从编写的代码中,编译器无法对线程间执行顺序的相互依赖做出推断。
本章我们会看到,Java 中提供了哪些机制,让我们人工地指定线程间的相对执行顺序。
共享可变状态(Shared Mutable State)
如果两个线程毫无交集,我们还会关心执行的先后顺序吗?谁先谁后都不影响最终的结果。如果两个线程多次读取了同一个变量,但从来不修改它,执行的先后有关系吗?这种情况下谁先谁后都不影响最终的结果。
线程安全问题发生的前提是:线程间存在着共享可变状态的行为。
直白地说,同一个变量,有的线程写入,有的线程读取,那么谁先执行谁后执行就会影响最终的执行结果。
Java 的多线程原语
说了这么久并发问题,我们还是没有说 Java 的内容,这里先简单提一提 Java 的同步原语,大家先有个印象。Java 语言提供的同步原语主要有三种:synchronized 和
volatile 关键字,还有JUC 包中的其它工具,如原子类AtomicInteger 等。而语法层面提供的只有 synchronized 和 volatile1。
这些高层的原语通常都会起到多个作用,如 synchronized 同时保证了原子性、可见性、和顺序性,如 volatile 保证了可见性和顺序性。
synchronized
Java 会为每个对象都生成一个监视器 monitor,可以用来 lock 或 unlock(通常也称为 moniter enter 和 moniter exit),JVM 保证同一时刻只有一个线程能拿到锁。其它获取锁的线程会被阻塞,直到该锁被释放。另外这个锁是“可重入”的,即一个线程可以获取锁多次,这种机制有有效减少死锁发生(但注意 Java 不保证检测死锁)。
synchronized 语句需要给定一个要上锁的对象,后面跟一个代码块代表临界区,代表需要同步执行的代码整体。如:
public withdraw(int x) {
synchronized (account) {
account.setBalance(account.balance - x);
}
}
也可以直接用来修饰函数:
public synchronized withdraw(int x) {
this.setBalance(this.balance - x);
}
如果不指定“上锁对象”,则默认使用 this,如果是静态方法,则默认使用类对象
(Class Object)。
synchronized 在执行时,会先拿到上锁对象的引用,然后尝试对该对象的监视器执行
lock 操作,得到锁后开始执行代码块里的操作,代码块执行结束后(不管是正常结束还是抛异常),会在同样的监视器上执行 unlock 操作释放锁。
这里只提到了锁的“原子性”,下面的 Happens Before 会定义 lock/unlock 的可见性和顺序性。
volatile
volatile 关键词在语法上比较简单,用来修饰变量:
private volatile balance;
直觉上,它说明一个变量是“易变的”,这意味着读写该变量的时候,缓存上的数据都不可靠,得从内存中读写。这个关键词语义主要关心的是可见性,不过下面的 Happens Before 除了会定义它的可见性,还会定义它的顺序性语义。
跨线程操作
在 Java 语言规范里说明了有哪些跨线程的操作(inter-thread actions)会影响线程安全,为了完整性这里全文列出:
- Read(normal, non-volatile),读取一个非 volatile 变量
- Write(normal, non-volatile),写入一个非 volatile 变量
- 同步操作
- volatile read: 读取一个 volatile 变量
- volatile write: 写入一个 volatile 变量
- lock: 给一个监视器(monitor)上锁
- unlock: 给一个监视器(monitor)解锁
- 线程的开始和结束(Java 会生成一个相应的操作)
- 启动线程和判断线程结束的操作
- 外部操作(External Actions),与外部世界交互的动作(可以简单理解成 native 方法)
- 线程分散操作(Thread Divergence Action),导致线程无限循环的操作
对我们来说,通常只关心 (volatile) read/write, lock/unlock。其它操作对于想实现 JVM 的同学们比较重要,对使用者来说,通常它们的行为符合直觉。
Happens Before
(注:初次看不太懂没关系,但建议后面再复习复习,HB 规则对深刻理解线程安全问题很有帮助)
Java Memory Model(JMM) 里定义了一些跨线程操作的 Happens Before(HB) 关系2,并据此来决定线程间一些操作的相对顺序。如果说操作 A "Happens Before" B,则有两个含义:
- 可见性:A 的操作对 B 可见
- 顺序性:A 要在 B 之前执行
我们把 Happens Before 关系记为 hb(A, B),本文也经常记为 A > B。
Happens-Before 规则包括3:
- 程序顺序规则:如果程序中操作 A 在操作 B 之前,那么在线程中操作 A Happens Before 操作 B
- 监视器锁规则:监视器上的 unlock 操作 Happens Before 同一个监视器的 lock 操作
- volatile 变量规则:写入 volatile 变量 Happens Before 读取该变量
- 线程启动规则:对线程
Thread.start方法的调用 Happens Before 线程内的所有操作 - 线程结束规则:线程中的任何操作 Happens Before 其它线程中检测到该线程的结束操作,要么是调用
join方法成功返回,要么是调用Thread.isAlive时返回false - 中断规则:一个线程在另一个线程上调用 interrupt Happens Before 被中断线程检测到 interrupt 调用(通过抛出 InterruptedExceptioin 或调用 isInterrupted 和 interrupted)
- finalizer 规则:对象的构造函数 Happens Before 该对象的 finalizer
- 传递性:如果
hb(A, B)且hb(B, C),则hb(A, C)
有了这些规则,加上在代码里使用正确的原语,编译器就能正确地在多线程语境下为我们的代码排序,如下例中使用了 synchronized 在同一对象上同步,如下图4:

Java 并没有定义两个 lock 操作的先后顺序,这意味着上图中编译器无法确定哪个线程先进入临界区,但如果如图左边线程先进入,我们就可以通过 unlock 和 lock 的 HB 关系做出一些推论:
- 可见性:右边线程在执行时,可以确定
x = 1,y = 1,因为左边线程 unlock 前的修改必须可见 - 顺序性:右边线程对
i, j的赋值不能先于右边线程对x, y的赋值
两者一起让我们可以推断出,右边线程执行后,结果一定是 i = 1, j = 1。
参考
HB 规则很重要,本身也不复杂,但需要较多的背景知识,这里推荐一些读物
- JSL Chapter 17 Java 语言规范,第 17 章专门讲并发问题
- 深入分析 java 8 编程语言规范:Threads and Locks 对上面这篇规范的讲解,对其中一些关键点的分析很不错
- JSR 133 正式和学术的文档,可以先看看其中非学习证明的部分。
- 书《Java 并发编程实战》,不多说了,必看书籍
小结
我们的理想是 Sequential Consistency,只可惜由于现实原因 JVM 无法为我们提供这样的保证,因此我们一直努力寻找多线程下的合理顺序保证。
本章中我们了解了只有“共享可变状态”的情形下,多线程间的先后顺序才会引发线程安全问题,之后列出了 Java 中的跨线程操作,最后学习了 Happens Before 的(非正式)的规则,以及 HB 规则如何帮助我们对程序运行结果做出推论。
现在,只要我们能正确地使用这些同步的原语,我们就能写出正确的(符合与 JVM 预期)的代码了。下一章我们来实战看看一些并发问题,以及如何 HB 关系来解决这些问题。
另外,对于想深入了解的同学,Happens Before 这个保证对于 JVM 而言还是太弱了,所以 JSR 133 里又提到了 Causality Model(因果模型)。这块对我们使用方来说不重要,我也不能全看懂,有兴趣的可以看看 JSR 133。
final 修饰的变量也有一些特殊的语义,本章先不提及,有兴趣的可以参考 JSL 第 17 章
示例来源于书本《Java 并发编程实战》
Happens Before 是一种偏序关系,偏序是集合上的一种关系,满足自反性(a<=a)、反对称(a<=b && b<=a => a = b)、和传递性(a<=b && b<=c => a<=c)。
参考《Java 并发编程实战》第 16 章,我觉得它比 JLS 17 章和 JSR 133 中的描述都要清晰
常见线程安全问题
之前的几章中,我们自底向上的地了解了并发编程的一些基本原理与限制,学习了Java 的 Happens-Before 机制,能用一些基本的原语来指定线程间的相对运行顺序。
通常以上层开发者的视角,能意识到有并发问题存在,并适时地使用 synchronized 加锁或用 java.util.concurrency(简称 JUC) 里的一些并发集合类(如ConcurrencyHashMap、ArrayBlockingQueue等)就可以了,这些工具已经对常用的并发需求提供了很好的抽象,它们的原子性、顺序性和有序性通常符合我们的直觉,不需要额外关心。
不过如果你想要了解这些抽象类的工作原理,或者有特殊需求需要做一些“骚操作”,那么就需要充分理解底层细节和影响。
本章中会罗列一些常见线程安全问题,一方面希望前面的理论知识能有用武之地,帮助我们理解一些极端条件下出现问题的原因;另一方面希望能识别一些常见的出现线程安全问题的使用模式。
参考
- https://hacks.mozilla.org/2019/02/fearless-security-thread-safety/
Time-Of-Check to Time-Of-Use
Time-Of-Check to Time-of-Use1 简称为 TOCTOU 或 TOCTTOU,是指在检查某个状态到使用某个状态之间存在时间间隔,而在这段间隔中,状态被其它人修改了,从而导致软件Bug 或系统漏洞。在《Java 并发编程实战》里,也称为“先检查后执行” (Check-then-Act)模式。
不管是写系统脚本、Java 程序、与数据库打交道,TOCTOU 都是常见的问题。我们先来看看“延迟初始化”(Lazy Initialization)问题2,它是一个典型的 TOCTOU 问题,也是几乎所有并发书籍会讨论的问题。
延迟初始化
延迟初始化的初衷是有一些初始化操作代价比较大,因此希望:
- 在调用时才真正执行初始化,不影响程序启动
- 初始化后,后续再调用方法,则使用的是初始化的结果
延迟初始化有多种表现形式,我们以“单例”(Singleton)的实现为例:
public static class LazyInitialization {
private static ExpensiveObject instance;
public static ExpensiveObject getInstance() {
if (instance == null) {
instance = new ExpensiveObject();
}
return instance;
}
}
开始时先判断 instance 是否为空,如果为空则执行初始化操作(new 一个
ExpensiveObject 对象),最后返回初始化完成的对象。这是一个典型的 TOCTOU 的操作。
问题在于,如果有两个线程同时执行这段代码,可能执行顺序如下:
--------------- Thread A ----------------+--------------- Thread B --------------
if (instance == null) { |
| if (instance == null) { // ①
| instance = new ExpensiveObject();
instance = new ExpensiveObject(); // ② |
return instance; // ③ |
| return instance; // ④
- ① 中,虽然线程 A 已经判断,准备初始化,但是由于初始化未完成,因此线程 B 的条件依旧满足,也会进行初始化
- 语句 ② 的执行,其实依赖 instance 为空,但实际执行时,这个条件已经被破坏了
- 于是在 ③ 和 ④ 中,线程 A 和线程 B 得到了不同的 instance,无法达到“单例”的效果。
解法:保证原子性
我们可以看到,TOCTOU 的主要问题在于状态的检查和状态的使用整体上不是原子的,而前面的章节中我们知道 Java 中最简单的实现原子性的方式是使用内置锁(intrinsic
lock),即 synchronized 关键字:
public static class LazyInitialization {
private static ExpensiveObject instance;
public synchronized static ExpensiveObject getInstance() {
if (instance == null) {
instance = new ExpensiveObject();
}
return instance;
}
}
在 getInstance 方法前加上 synchronized 关键词,可以保证在同一时刻,只可能有一个线程在执行 getInstance 内的逻辑。这样保证了只会有一个线程在检查
instance 是否为空,且在状态使用之前,instance 不会被其它线程更改。换句话说,在状态的使用时,检查时得到的条件依旧成立。
当然,synchronized 是互斥锁,意味着即使初始化正确完成后,依然只有一个线程能执行代码,于是在高并发下性能不好,之后的章节中会介绍如何优化。
Java 外的 TOCTOU
Java 中的并发问题从形式上和使用数据库时遇到的并发问题很像,TOCTOU 问题也常见于数据库的使用中,例如使用数据库记录 API 的调用次数,则流程上,相当于一个事务中需要处理如下逻辑:
SELECT api_count FROM table WHERE name = '...';
(in Java: new_api_count = api_count + 1;)
UPDATE table SET api_count = <new_api_count> WHERE name = '...';
考虑有两个线程或进程同时执行这段逻辑,则同样的,可能出现:
------------- Process A -----------------+------------ Process B ----------------
SELECT api_count FROM ... (=10) |
| SELECT api_count FROM ... (=10)
| new_api_count = api_count + 1 (= 11)
new_api_count = api_count + 1 (= 11) |
UPDATE table SET ... (= 11) |
| UPDATE table SET ... (= 11)
于是预期是累加了两次,最终结果为 12,但由于并发问题导致了写丢失(Lost update)。
同上,要解决这个问题要想办法保证原子性,在 MySQL 里有两种方法:
- 使用
SELECT ... FOR UPDATE加上悲观锁,保证后续操作的原子性 - 将 java 中实现的累加操作换成 MySQL 提供的原子操作:
UPDATE table SET api_count = api_count + 1 WHERE name = '...'
小结
TOCTOU 问题的根源是使用状态时,其实依赖了之前的状态检查结果,而在检查到使用的这段时间里,状态被其它线程/进程修改了,于是依赖的条件被打破,使得对状态的使用不再正确。
解法是:将状态的检查和使用作为整体用锁保护起来,保证整体的原子性。Java 里最方便的是synchronized关键词,当然也可以用如 ReentrantLock 等机制。
其实线程安全问题,就是因为由代码顺序带来的逻辑预期被破坏了。如上例中,在执行初始化时经过了 if (instance == null) 的判断,instance == null 是初始化的大前提,但在执行时大前提被破坏了,此时再执行初始化本身就是错误的行为。
https://en.wikipedia.org/wiki/Time-of-check_to_time-of-use
例如知名 RPC 框架 dubbo 中的 NetUtils 使用了延迟初始化来获取本机 IP
Double Checked Locking
双重锁定检查(Double Checked Locking,下称 DCL)是并发下实现懒加载的一个模式,在实现单例模式时很常见,但是要正确实现 DCL,其中涉及到的细节和知识是非常琐碎的,我们这里按照 The "Double-Checked Locking is Broken" Declaration 文章的脉络,结合前几章学习的知识,尝试理解这些知识点。
(这章属于“骚操作”的内容。)
初次尝试
上节中说过 Lazy Initialization,我们的目标是在获取某个实例时只初始化一次,在单线程语境中,我们会这么实现:
class Foo {
private Helper helper = null;
public Helper getHelper() {
if (helper == null)
helper = new Helper();
return helper;
}
// other functions and members...
}
但是我们知道这个版本在多线程下是有问题的,因为对 helper 和检查和赋值不是原子的,有可能多个线程同时满足了 if (helper == null) 的判断,最终多个线程都执行了
helper = new Helper 的操作。一个简单的方法是加锁:
class Foo {
private Helper helper = null;
public synchronized Helper getHelper() {
if (helper == null)
helper = new Helper();
return helper;
}
// other functions and members...
}
注意代码里的 synchronized。这个代码能正确运行,但是效率低下,因为
synchronized 是互斥锁,后续所有 getHelper 调用都得加锁。于是我们希望在
helper 正确初始化后就不再加锁了,尝试如下实现:
class Foo {
private Helper helper = null;
public synchronized Helper getHelper() {
if (helper == null) // ① 第一次检查
synchronized(this) { // ② 对 helper 加锁
if (helper == null) // ③ 同上个实现
helper = new Helper();
}
return helper;
}
// other functions and members...
}
代码的初衷是:
- 如果正确初始化后,所有的
getHelper① 的条件失败,于是不需要synchronized - 如果未被正确初始化,则同上个实现一样,加锁进行初始化。
Unfortunately, that code just does not work in the presence of either optimizing compilers or shared memory multiprocessors.
很可惜,这段代码在编译器优化或多核的环境下是“错误”的。在这章中,我们会尝试去理解为什么它不正确,及为什么一些 bugfix 后依旧不正确。丑话说在前:
There is no way to make it work without requiring each thread that accesses the helper object to perform synchronization.
用人话来说,就是如果不把 helper 对象设置成 volatile 的,这段代码就不可能正确。
指令重排
第一个可能的问题是重排序1。这行代码 helper = new Helper(); 看上去是原子,从字节码的角度可以理解成下面几个步骤:
instance = Helper.class.newInstance(); // 1. 分配内存
Helper::constructor(instance); // 2. 调用构造函数初始化对象
helper = instance; // 3. 让 helper 指向新的对象
前面章节说过,JVM 可能会对指令做重排序,所做的保证是不影响“单线程”的执行结果,那么可能排序成这样:
instance = Helper.class.newInstance(); // 1. 分配内存
helper = instance; // 3. 让 helper 指向新的对象
Helper::constructor(instance); // 3. 调用构造函数初始化对象
那么在 #3 执行之前,helper 指向的内存地址未被初始化,是不安全的。在多线程下,可能会变成:
--------------- Thread A -------------------+--------------- Thread B --------------
if (helper == null) |
synchronized(this) { |
if (helper == null) { |
instance = Helper.class.newInstance();|
helper = instance; |
| if (helper == null) // false
| return helper
| // ... do something with helper.
Helper::constructor(instance); |
} |
} |
return helper; |
即由于重排,helper 指针已经有值了,但是还未初始化,导致此时线程 B 拿着未初始化的 helper 做了其它的操作,这是有风险的。
注意的是,即使编译器不做重排序,CPU 和缓存也可能会做重排序。
试图挽救重排序
上面的问题,我们根本目标是要保证 synchronized 块结束时(初始化完成后),相应的值才被其它线程看到,于是我们可以用下面这个 trick:
class Foo {
private Helper helper = null;
public Helper getHelper() {
if (helper == null) {
Helper h; // ① 创建了临时变量
synchronized(this) {
h = helper; // ② 保证读取最新的 helper 值
if (h == null)
synchronized (this) { // ③ 尝试用内部锁解决重排序
h = new Helper(); // ④ 创建新的实例
} // ⑤ 释放了内部的锁
helper = h; // ⑥ 将新的实例赋值给 helper
}
}
return helper;
}
// other functions and members...
}
这里的想法是想通过 ③ 处的锁来阻止重排序,更准确地说,是希望在 ⑤ 释放锁的地方能提供内存屏障(memory barrier),从而保证 h = new Helper 一定在 helper = h
之前执行。
很可惜这个“希望”现实中不成立。Happens Before 里规定的是:
监视器上的 unlock 操作 Happens Before 同一个监视器的 lock 操作
换言之,为了保证 unlock Happens Before 其它的 lock 操作,JVM 需要保证在锁释放时,synchronized 块之前的操作都已经完成并写回到内存里。但是这个规则并没有说 synchronized 块之后的操作不能重排序到synchronized 块之前执行。因此上面这种修改的“美好希望”实际上并不成立2。
此路不通
即使我们真的能保证 helper 在被赋值之前就已经正确初始化了3,这种方式就能正确工作了吗?不能。
问题不仅仅在于写的一方,即使 helper 被正确初始化并赋值,由于另一个线程所在的
CPU 可能会从缓存中读取 helper 的值,如果 helper 的新值还没有被更新到缓存中,则读取的值可能还是 null。
等等!不是说 synchronized 会保证可见性吗?是的,但它保证的是 unlock 操作前的更新对同一个监视器的 lock 操作可见,但现在另一个线程根本没有进入
synchronized 代码块,此时 JVM 不保证可见。
volatile
经过前面的分析,想起了前面章节提到的 volatile 关键字(JDK 1.5 后支持)有这么一条 Happens Before 规则:
volatile 变量规则:写入 volatile 变量 Happens Before 读取该变量
它可以提供额外的可见性保证。于是我们可以这么(正确)实现:
class Foo {
private volatile Helper helper = null; // 注意变量声明了 volatile
public Helper getHelper() {
if (helper == null) {
synchronized(this) {
if (helper == null)
helper = new Helper();
}
}
return helper;
}
}
这个实现里,写入 helper 之前的操作,如 Helper 对象的初始化,在 helper 被读取(如判断 helper == null)必须可见。换句话说,前文讨论的两种情况:重排序与可见性问题都由于 volatile 的语义得到保证。
那么 volatile 是不是会降低性能?《Java 并发编程实战》第三章的注解里说
在当前大多数处理器架构上,读取 volatile 变量的开销只比读取非 volatile 变量的开销略高一点
几个例外
例外不是说 volatile 方式的正确性有例外,而是对于一些特殊情形,有特殊的解法。
static 单例
对于是 static 的单例,最好的初始化方式是利用 Java 类加载机制,如下:
public class Foo {
private static class Holder {
private static Helper helper = new Helper();
}
public static Helper getInstance() {
return Holder.helper;
}
}
32 位 primitive
这里的知识点是 32 位的 primitive 类型变量的读写是原子的。如果初始化的方法是幂等的,则可以这么实现:
class Foo {
private int cachedHashCode = 0;
public int hashCode() {
int h = cachedHashCode;
if (h == 0)
synchronized(this) {
if (cachedHashCode != 0) return cachedHashCode;
h = computeHashCode();
cachedHashCode = h;
}
return h;
}
// other functions and members...
}
当然,如果方法是幂等的,甚至都不需要同步:
class Foo {
private int cachedHashCode = 0;
public int hashCode() {
int h = cachedHashCode;
if (h == 0) {
h = computeHashCode();
cachedHashCode = h;
}
return h;
}
// other functions and members...
}
为什么一定需要 32 位呢?因为 64 位的操作不是原子的,于是可能造成前后 32 位不是一起写入内存的,而另一个线程只读取先写入的 32 位,读到的结果不正确。
final
如果前文的 Helper 类是不可变的(immutable),具体地说,Helper 的所有属性都是
final 的,那么即使不加 volatile,DCL 也是正确的。这是因为 JVM 对 final
关键字有一些特殊的语义,有兴趣的可以参考 JSL 第 17 章
小结
本章中我们讲解了 The "Double-Checked Locking is Broken" Declaration 文章中关于 DCL 的各个示例,并结合前面章节中学到的 Happens Before 关系的知识去理解 DCL 成立或不成立的原因。
有时候我们会认为:写的时候加锁就行了,读操作不需要加锁。本节的例子就说明了这种观点不成立,会有可见性和顺序性的问题。最简单的解决方式是读操作也加锁,如果性能达不到要求,也可以像本节一样使用 volatile,但我个人不建议这么用,因为有太多细节需要考虑,可以使用 JUC 中的 ReadWriteLock 来加读写锁。
可以看到,要正确地实现并发程序,难度是很大的,并且要了解很多细节。当然也不必灰心,已经有前人为我们辅好了路,日常工作中我们只需要跟随前人的脚步,就可以满足绝大多数需求。
参考 CSDN 文章 双重检查锁定(double-checked locking)与单例模式
关于重排序和内存可见性,可以参考 Doug Lea 的 The JSR-133 Cookbook for Compiler Writers
这里介绍了一种方法,不要用在生产中
复合操作
复合操作的问题本质上和 TOCTOU 是一样的,如果有多个操作(如同一变量的读写)就有可能出现线程安全问题。
不过在本节我们要强调的是,即使每个操作本身是原子的,复合操作也不是原子的,这种情形有时候比较难一眼就认出来。
示例
这里以《Java 并发编程实战》第二章的“因式分解”代码为例:
@NotThreadSafe
public class UnsafeCachingFactorizer implements Servlet {
private final AtomicReference<BigInteger> lastNumber = new AtomicReference<>();
private final AtomicReference<BigInteger[]> lastFactors = new AtomicReference<>();
public void service(ServletRequest req, ServletResponse res) {
BigInteger i = extractFromRequest(req);
if (i.equals(lastNumber.get())) { // ①
encodeIntoResponse(resp, lastFactors.get()); // ②
} else {
BigInteger[] factors = factorOf(i);
lastNumber.set(i); // ③
lastFactors.set(factors); // ④
encodeIntoResponse(resp, factors);
}
}
}
这个例子中 lastNumber 用来记录上一次做过“因式分解”的数,lastFactors 存放上次因式分解的结果。service 中先判断 lastNumber 是否与请求的数相等,如果相等则使用存储的 lastFactors;反之不相等则需要重新计算因式分解,并把结果存入
lastNumber 与 lastFactors 中。
这里 lastNumber 与 lastFactors 都用了 AtomicReference,它们是 JUC 中的类,可以理解为已经达到了原子性、可见性与顺序性。所以代码中的 ①②③④ 处的 get
set 都是原子的,只不过复合操作的问题是,即使每个操作都是原子的,操作整体也不是原子的。
这个示例比较精妙的地方在于它很符合我们的编码习惯,如果不仔细思考甚至都发现不了它存在线程安全问题。
问题时序
考虑线程 A 与线程 B 同时进入 else 语句,且分别需要求得 2 和 3 的因式分解,考虑下面的时序:
----------- Thread A ---------------+--------- Thread B -----------------
lastNumber.set(i); (=2) |
| lastNumber.set(i); (=3)
| lastFactors.set(factors); (=[1,3])
lastFactors.set(factors); (=[1,2]) |
则最终结束后 lastNumber = 3,lastFactors = [1,2],则下次请求如果是分解 3
,则会使用 lastFactors 的值,得到结果 [1,2],是错误的结果。
另一方面,也有可能是这样的时序:
----------- Thread A ---------------+--------- Thread B -----------------
lastNumber.set(i); (=2) |
| if (i.equals(lastNumber.get())) (= 2)
| encodeIntoResponse(resp, lastFactors.get());
lastFactors.set(factors); (=[1,2]) |
这个时序里,一个线程计算了 2 的结果,正在写回缓存,过程中另一个线程请求因式分解 2,此时 lastNumber = 2,因此返回了 lastFactors 的内容,但线程 A 关于 2 的结果还未写回 lastFactors,线程 B 返回了一个错误的结果。
当然,也有可能是这样的时序:
----------- Thread A ---------------+--------- Thread B -----------------
Initial Value of lastNumber: 2 |
| if (i.equals(lastNumber.get())) (= 2)
lastNumber.set(i); (=3) |
lastFactors.set(factors); (=[1,3]) |
| encodeIntoResponse(resp, lastFactors.get()); (=[1,3])
不成熟的解法:同步方法
从 TOCTOU 一节中我们知道,要解决这种竞争问题,需要把对状态的检查与使用都变成原子的,最简单的方式就是在方法上用 synchronized:
@ThreadSafe
public class UnsafeCachingFactorizer implements Servlet {
// .. 省略代码
public synchronized void service(ServletRequest req, ServletResponse res) {
// .. 省略代码
}
}
但是这个方法太极端了,所有的请求线程调用 service 方法都需要同步,同一时间只能有一个线程执行该方法,完全失去了多线程的优势。
解法:减小粒度
给整个方法加锁十分简单,但是由于锁的粒度很粗,并发性差。而我们的真实需求其实有两个:
- 对
lastNumber和lastFactors的赋值操作需要是原子的 - 对
lastNumber和lastFactors的读取也需要是原子的(至少读取过程中不允许赋值)
因此我们可以用 synchronized 代码块,实现如下:
public class UnsafeCachingFactorizer implements Servlet {
private BigInteger lastNumber;
private BigInteger[] lastFactors;
public void service(ServletRequest req, ServletResponse res) {
BigInteger i = extractFromRequest(req);
BigInteger[] factors = null;
synchronized (this) { // ①
if (i.equals(lastNumber.get())) {
factors = lastFactors.clone();
}
}
if (factors == null) {
factors = factor(i);
synchronized (this) { // ②
lastNumber = i;
lastFactors = factors;
}
}
encodeIntoResponse(resp, factors);
}
}
在 ① 中把读操作用 synchronized 代码块保证原子性,在 ② 中用同样方法保证赋值的原子性。另一个关键点是,两个代码块需要加同一个锁,此处直接用了 this,是最稳妥的选择,当然也可以锁其它的 object,只要两个块加同一个锁即可。
另外此处因为使用了 synchronized,对 lastNumber 和 lastFactors 不再需要使用原子类。通常原子类(如 AtomicReference) 对单个操作的原子性保证很方便,但复合操作本身需要加锁,这里再使用原子类就显得没必要了。
小结
复合操作即使操作本身是原子的,复合操作作为一个整体本身也不具备原子性。所以和 TOCTOU 问题一样,解决方法是需要加锁来保证复合操作整体的原子性。
还有一点比较特殊,是我们看到“读操作”和“写操作”一样,都是必须要加锁的。
示例中我们也看到,并发编程是在简单性与并发性中的权衡。锁的粒度粗了,使用起来简单,但是并发性低,也许就满足不了性能要求;反之锁的粒度细了,并发性提高了,但是复杂度也随之增加,稍有不慎就容易有线程安全问题。
小结
本章中我们举例讲解了 TOCTOU 问题、DCL 机制和复合操作问题。
TOCTOU 告诉了我们最最常见的需要加锁的模式;而 DCL 告诉我们如果想做一些“骚操作”(如不加锁),则需要掌握很多细节(如可见性、有序性);复合操作本质上和 TOCTOU 是一样的问题,只是表现形式更“新颖”一些,同时在解决的过程中我们意味到了在具体实现中,需要权衡“锁粒度”。
其实线程安全问题的“本质”还是比较简单的:一定是存在共享的可变状态。只是这个“本质”的外在体现多种多样,实际上很难快速鉴别,需要凭借经验。最好的治病是预防,在编码过程中尽量遵循一些原则,可以大幅减少可能出现的问题,这也是我们下一章要探讨的内容。
良好并发编程习惯
最好的治疗是预防。本章会结合《Java 并发编程实战》第三、四章的内容,以及 MIT 6.005 - Reading 20: Thread Safety 一文,讲讲一些“理论”上的预防并发问题的编程习惯。
我们前面说过,线程安全问题发生的前提是:线程间存在着共享的可变的状态(Shared Mutable State),因为这种情况下,程序的正确性依赖了底层操作的某些特定顺序。也因此,有几种常见的保证线程安全的方式:
- 封闭(Confinement),简单地说,就是不要在线程间共享状态
- 不可变(Immutability),可以共享,但是共享的变量“不可变”1
- 线程安全类(Threadsafe Data Types),用已有的线程安全类来封装共享的状态,不需要自己实现同步
- 同步(Synchronization),万不得以必须自己实现共享可变状态,需要通过同步保证运行顺序
“不可变”不单纯指“不修改”,因为还会有可见性问题,后面我们会详细说明
封闭(Confinement)
“共享可变状态”有两个要点:“共享”和“可变”。封闭的策略是:不共享就完事了。
《Java 并发编程实战》一书中列举了三种封闭的方式。
- Ad-hoc 线程封闭
- 栈封闭
- ThreadLocal 类
Ad-hoc 封闭
"Ad-hoc" 一般指“特别的、专门的、临时的”等,在编程的语境中一般指“具体情况具体分析”。Ad-hoc 封闭也就指由程序自己实现的封闭。
例如有个 volatile 变量,在编写代码的时候,隐含实现了这样的约定:只有一个线程会“写”该变量,其它线程只会“读”操作。那么这种情况下这个“写线程”即使做了 "Check-then-Act" 操作也是线程安全的。
所以 Ad-hoc 封闭也只能是“具体情况具体分析”了。
栈封闭
局部变量(local variables)在方法调用时被分配到栈上,正常情况下当方法返回时就被销毁(不再被引用,可以被 GC 回收),只存在于调用的线程中。这些变量由于不会被共享,即使变量本身并不是线程安全的,也不用担心方法的线程安全性。
当然如果局部变量通过一些方式在方法调用结束后依旧被引用,则不再是“封闭”的,就会有线程安全的问题。如变量被作为方法的返回值被返回;被方法里创建的线程引用;引用被保存到了其它地方,如实例变量(instance variable)等。
一般如果一个方法只依赖它的输入参数和方法内创建的局部变量,不依赖其它的全局的信息,则可以说这个方法是“无状态”的。
ThreadLocal 类
ThreadLocal 也可以认为是前文所说的“线程安全类”,只不过 ThreadLocal 的语义上就是“线程封闭”的。
ThreadLocal 的作用是为每个线程保存一个副本,每个线程在调用 get 或 set 方法时都只会操作本线程的副本。由于每个线程只用自己的那份,不存在共享行为,因此是线程安全的。
一般来说,如果有一些对象从作用是可以做成单例,但它本身又不是线程安全的,就可以使用 ThreadLocal 为每个线程创建一个副本,就可以线程安全地把它作为单例使用了。
例如,我们知道 SimpleDateFormat 不是线程安全的,但是通过 ThreadLocal 的包装,就可以做到线程封闭,不在线程间共享,做到线程安全,如下示例1:
public class DateUtil {
private static ThreadLocal<SimpleDateFormat> dateFormat = ThreadLocal
.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));
public static String formatDate(Date date) throws ParseException {
return dateFormat.get().format(date);
}
}
要注意的是,由于需要为每个线程创建一个副本,如果初始化的代价比较高且经常性地创建新的线程,可能会有潜在的性能问题,虽然通常情况下不会成为问题。
另外,不要把从 ThreadLocal 获取的引用保存到其它地方,会有潜在的线程安全问题。
小结
封闭策略用人话来说就是:尽量不要用全局变量,如果全局变量是单例,考虑用
ThreadLocal 包装。
尽管如此,Java 8 后还是推荐使用线程安全的 DateTimeFormatter
不可变(Immutability)
如果说“封闭”是通过“不共享”来解决线程问题,顾名思义“不可变”就是从可变性入手解决线程安全问题:
不可变对象一定是线程安全的
不可变对象的状态在构造函数中就唯一确定了,之后不接受任何的更改,因此编译器能对它做更可靠的优化,更容易保证它的线程安全性。
不可变对象的门槛
我们很容易认为,如果创建一个对象后,没有任何代码修改它,它就是“不可变”的。很可惜这种观点是错误的,在 Java 中,不可变对象有着明确的要求1:
- 对象创建后其状态不能修改
- 对象所有的成员变量都是
final修饰的 - 对象是正确创建的(在对象的创建期间,this 引用没有逸出)
创建后状态不能修改,例如类中有一个字段是 private final Set<String> names,虽然 names 引用本身不能修改(有 final 修饰),但技术上我们却可以向 Set 里增减元素。而不可变要求我们不能做这样的修改。实际上 Java 并不会做这些检测,只是如果不遵守这个规则,则不能保证对象就是线程安全的。
成员变量都是 final 修饰,实际上这是 Java 真正能检测到的内容。Java 会保证
2 只有当一个对象的所有 final 成员变量都正确初始化后,该对象才对其它线程可见。
对象是正确创建的,反例是在构造函数内,将 this 指针传递给其它对象使用。例如在构造函数中启动新的线程,这个新的线程中使用了 this 指针。为什么要求对象是“正确创建”的呢?是因为 Java 需要保证不可变对象的可见性,但是无法在构造函数执行过程中,做到可见性保证,因此其它对象在构造函数中通过 this 访问某个成员变量,得到的值可能是有问题的。
基于可变对象构造不可变对象
虽然说要求“创建后状态不能修改”,但在“创建时”却可以修改,考虑如下示例1:
public final class ThreeStooges {
private final Set<String> stooges = new HashSet<>();
public ThreeStooges() {
stooges.add("Moe");
stooges.add("Larry");
stooges.add("Curly");
}
public boolean isStooge(String name) {
return stooges.contains(name);
}
}
这里 stooges 变量显然是可变的,并且在构建函数中做了修改,但是类
ThreeStooges 依旧是不可变的,因为对(final变量的)状态修改发生在构造函数内。依旧符合不可变对象的定义。
往底层了说,是因为 JMM 规定,在构造函数内对 final 成员变量引用的对象的修改,不能重排序到构造函数之外3,这意味着当某个线程在访问某个对象的
final 变量时,构造函数里对 final 变量的修改都一定是完成并可见的。
使用 volatile 发布不可变对象
“发布”(publish)这个概念之前我们一直没有提,“发布对象”指的是使对象在当前作用域之外可访问,例如保存对象的引用;在非私有的方法里返回对象;或将引用传递到其它类的方法中。这个概念的核心是“共享”,“发布”是一个共享的操作。当一个对象被发布后,我们无法控制其它线程会如何使用它,因此如果对象本身不是线程安全的,那么使用方如果不注意,就很容易出错。
如果发布的是不可变对象,由于它本身是线程安全的,我们就不用担心使用方误用。例如《Java 并发编程实战》中的 OneValueCache 示例:
class OneValueCache {
private final BigInteger lastNumber;
private final BigInteger[] lastFactors;
public OneValueCache(BigInteger i, BigInteger[] factors) {
lastNumber = i;
lastFactors = Arrays.copyOf(factors, factors.length); // ①
}
public BigInteger[] getFactors(BigInteger i) {
if (lastNumber == null || !lastNumber.equals(i))
return null;
else
return Arrays.copyOf(lastFactors, lastFactors.length); // ②
}
}
OneValueCache 是一个不可变类,代码中 ① ② 处分别用了 Arrays.copyOf 来复制输入的 factors 数组和输出的 factors。如果这两处不复制,OneValueCache 就不再是严格意义上的不可变了,因为我们无法控制 OneValueCache 类之外对构造函数输入的 factors 引用做什么修改,也无法控制对 getFactors 返回的 lastFactors
引用做修改。
当然,如果你说你不需要那么强的要求,直接在文档写了“不要修改 factors”并假设没有人会修改,这样不用 copyOf 行吗?当然没问题,这就是“约定” vs “机制”的问题了,约定技术上是可能被打破的,机制不会但代价高。
有了 OneValueCache 我们就可以发布它:
public class VolatileCachedFactorizer implements Servlet {
private volatile OneValueCache cache = new OneValueCache(null, null);
public void service(ServletRequest req, ServletResponse resp) {
BigInteger i = extractFromRequest(req);
BigInteger[] factors = cache.getFactors(i);
if (factors == null) {
factors = factor(i);
cache = new OneValueCache(i, factors);
}
encodeIntoResponse(resp, factors);
}
}
在“复合操作”一节中我们说过这个例子,说的是即使 lastNumber 与 lastFactors
本身都是原子的,整体操作也不是原子的。
现在我们通过不可变类 OneValueCache 将两个状态合二为一,这样从“可见性”的角度上,它就是原子的了,即如果我看到 lastNumber 的值,那么 lastFactors 一定是和它对应的结果。
当然,这个例子依旧会有 TOCTOU 的问题,可能有两个线程同时进入 factor(i) 的计算,但由于这个例子的业务上是用 cache 来做缓存,所以最终无论谁的值进缓存都不会影响正确性。
最后,成员变量标为 final 的不可变类 OneValueCache 起到什么作用?
这个问题书里没有回答,通过看一些文章和逻辑上的分析,我得出的结论是这样的:
- 这个例子里要解决两个问题:
- 对 cache 的读写操作需要是原子的,因为只涉及一个引用的读写,已经满足
- 要保证可见性和有序性,保证其它线程看到 cache 时,
OneValueCache已经是正确初始化了
- 本例中使用了
final和volatile,二者都可以满足 1.ii 的需求 - 因此本例中其实
final和volatile只需要一个就可以了 - 不过如果不加
final只用volatile,则拿到cache引用的线程还可能做修改,只能做到“约定”上的线程安全。
小结
“不可变对象”解决了“共享可变状态”中的“可变”问题。
我把“不可变”分成了“约定上”的和“机制上”的不可变。不可变对象在 Java 中主要需要解决的是“可见性”和“有序性”的问题,要保证线程看到对象时,对象已经是正确初始化的,而约定上的不可变并没有这个保证。
在 Java 中,机制上的不可变最核心的是要给类的成员变量加上 final 修饰,因为
Java 会对 final 修饰的字段做可见性和顺序性的保证。但如果 final 字段本身引用了另一个对象,Java 并没有机制能保证这个对象的线程安全。
细节上,如果只是在对象的构造函数中修改 final 成员变量引用的对象,Java 也会保证这些修改的可见性,我们给了一个例子说明如何基于可变对象构造不可变对象。
理论上真正的不可变对象,还要求对象创建后其中的状态就不再修改,如果对象不提供任何修改内部状态的手段,我们就能百分百确定对象发布后是线程安全的。只是 Java 并没有提供相关的机制来强制这个行为。
从编码的习惯上,不可变(Immutability)是很值得提倡的,不论对并发编程还是单线程编程,它能极大地减少程序可能的状态,更容易 Debug,更不容易出错。
摘抄自《Java 并发编程实战》
JSL 第 17 章 有关于 final 语义的详细介绍
线程安全类
学习并发编程很重要的一个思维转变是意识到并承认并发编程是十分困难的1。很多时候最聪明的方法是复用已有的成果,不要重复发明轮子。
根据数据的映射关系是一对一、一对多还是多对多,数据结果可以分成表(List)、树( Tree)和图(Graph)。而通常对应的底层结构有列表(List)、集合(Set)和映射( Map)。除了像 int, long, double 这样的原始类型,几乎所有需要聚合的数据都可以划分成这三类(甚至类也可以认为是成员变量名字到值的映射)。也因此,常见的并发需求通常也集中在对集合(collection)类的读写上。
JDK 1.5 新增的 java.util.concurrent(简称JUC)包中,实现了许多线程安全的集合类。我们日常开发中的并发需求,通常用 JUC 中的类替换相应的原始类型或集合类,就可以达到线程安全。例如用 ConcurrencyHashMap 替换 HashMap 可以实现 Map 读写的线程安全。
因此虽然我们学习了好几章并发知识,实际日常开发中通常只需要使用 JUC 里的线程安全类就能解决绝大多数问题。
JUC 简介
Java 只提供了 synchronized 和 volatile 两种同步原语,在性能要求高的一些场景下,用它们来实现细粒度的同步会极大增加代码的复杂程度,性能也不好。Doug Lea大神在 1998 年实现了
EDU.oswego.cs.dl.util.concurrent
并发工具包来解决这些问题。这个实现的语义和性能都十分优秀,在 Java 1.5 中通过
JSR 166 被合并进 JDK 中,成了现在的
java.util.concurrent 包。从此 Java 程序员们就拥有了其它语言开发者们艳羡的并发工具。
JUC 的内容丰富,本节不会详细介绍,这里我们先看看整体包含的内容:
- locks 提供了粒度更细的一些锁的语义
- atomic 和 collections 提供了线程安全的类,几乎能满足日常并发下的存储需求
- executor 提供了线程池相关的工具,解决日常的并发调度需求

(上图参考 深入浅出 Java Concurrency (1) : J.U.C的整体认识 制作,且以 Java 8 为准)
一些注意点
有并发的地方就需要用线程安全类。虽然可能显而易见,要注意的是只有包装类提供的方法才保证是原子的,而里面存储的内容则没有。例如 ConcurrencyHashMap<String, HashMap<String, Card>> accounts; 外层 ConcurrencyHashMap 存储的是“人”到“帐户”的映射,内层 HashMap 存储的是这个人的“卡号”到“卡信息”的映射。那么如果并发直接对内层信息进行修改,是保证不了线程安全的。
迭代器不是原子的。线程安全的集合类只有提供的方法是原子的(如get()、put()等),由于并没有全局锁(也不应该有),从集合类中获得的迭代器(Iterator
)不是线程安全的,如:
for (Map.Entry<String, Object> entry: concurrentMap) {...} // 线程不安全
TOCTOU 问题依旧存在。尽管线程安全类提供的方法本身是原子的,前面说过,基本操作是原子的不代表复合操作是原子的,如:
ConcurrencyMap<String, Object> cache = new ConcurrencyHashMap<>();
// ...
if (cache.containsKey(x)) {
return cache.get(x);
}
尽管 cache.containsKey 与 cache.get 方法都是原子的,但可能在 get 之前,由另一个线程执行了 remove,导致 get 失败,或执行了另一个 put 导致 get
的数据不符合预期。
幸运的是 JUC 类中提供了一些常见的原子复合操作,例如 ConcurrencyHashMap 中的
putIfAbsent 只有当key 不存在时才执行函数并插入,computeIfPresent 只有当
key 存在时才执行某个变换操作。
小结
本节内容不多,却可能是最实用的一节。日常的线程安全问题通常会落在原始( primitive)类型和集合(Collection)类,而使用对应的线程安全类通常就能直接解决问题。
JUC 是线程安全类的佼佼者,值得深入使用和学习。
不过即使使用线程安全的包装类,也要注意它们的“安全”边界在哪里。
大家可以看看 JDK 11 的 ReadWriteLock 中的 "Sample usages" 示例,实际上是有问题的(rwl.readLock().lock(); 应该要放在 finally 中)。强如官方文档,都会出错。
思考题
Spring Bean 初始化如何保证线程安全
Spring Bean 中的参数通常有几种初始化方法:
通过构造函数注入:
@Service
public void MyService {
private MyData myData;
public MyService(MyData myData) {
this.myData = myData;
}
}
通过 setter 注入:
@Service
public void MyService {
@Autowired
private MyData myData;
}
也有可能在 PostConstruct 中指定初始化逻辑:
@Service
public void MyService {
private MyData myData;
@PostConstruct
public void init() {
this.myData = new MyData();
}
}
我们知道 Spring 默认创建的 Bean 是单例的,那么 Bean 中的字段需要声明成
volatile 吗?
可能有问题
由于是单例,意味着 MyService 可能被多个线程并发使用,使用典型的使用场景:
@Controller
public class MyController {
@Autowired private MyService myService;
@GetMapping("/data/{id}")
public Response fetchData(@PathVariable long id) {
return myService.fetchData(id);
}
}
由于 MyController 中的 API 可能会被并发访问,于是 myService 也会在多线程中并发调用。
问题是:在某个线程中访问 myData 时,myData 被正确初始化了吗?
构造函数、重排序与可见性
其实我们之前在 Double Checked Locking 中提过这个现象,考虑这样的语句:
MyData myData = new MyService(); |
| this.myData = myData;
| this.myData.someFunc();
有可能因为重排序和可见性的原因,变成:
MyData myData = MyData.class.newInstance(); |
| this.myData = myData;
| this.myData.someFunc();
MyData::constructor(myData); |
也就是说在 myService.fetchData 被调用时,myService 中看到的 myData 可能还未正确初始化。
Plain Java 的解法
你可能二话不说,直接把 myData 申明成 volatile:
@Service
public void MyService {
private volatile MyData myData;
}
当然没有问题,如果你对性能要求更高,并且还记得 final 的特殊语义,那么会这么干:
@Service
public void MyService {
private final MyData myData;
public MyService(MyData myData) {
this.myData = myData;
}
}
final 能保证当 MyService 构造函数返回时,myData 已经被正确初始化了,但是代价是不再能用 setter 注入和 PostConstruct 的初始化方式。
那么在 Spring 里呢?我们并没有加 volatile 的习惯,那是在作死吗?
Spring 如何保证线程安全
事实上 Spring Bean 中的字段,并不需要显式指定为 volatile,原因如下:
- Spring 的 Bean 会存储在一个 map 中(
DefaultSingletonBeanRegistry.singletonObjects) - 每次存储或获取某个 Bean,都会显示在这个 map 上加内置锁(synchronized)
- 由于 JMM 的“监视器锁规则”,lock 能看到同一个监视器的 unlock 前的变化
于是,我们只要注入了某个 Bean,那么这个 Bean 的初始化的内容就是可见的,上例中,在 MyService 中看到了 myData 这个 Bean,就可以保证 myData 已经被正确初始化了。并且这里的初始化不仅仅指构造函数中的内容,而是 Spring 语境下的初始化,还包括setter 注入,PostConstruct 初始化等。
但是要注意,这个机制要求 Bean 的初始化和获取都是通过 Spring 完成的。如果 Bean 初始化后又做了修改,或者 Bean 不是通过 ApplicationContext 或 Autowired 获取的,则没有这个可见性保证。
小结
在 Spring Bean 的初始化中,我们通常不需要显式地指定某个字段是 volatile,是因为
Spring 有相关机制做了保证。这个机制依赖了 synchronized 关键字与 监视器锁规 则。
参考
- https://stackoverflow.com/a/23992532/826907 SO 的回答,基本涵盖了上面所说的内容
- Spring and visibility problems 一篇提到上述机制的博文
- DefaultSingletonBeanRegistry.java Spring 源码,管理单例 Bean 的相关功能
Amdahl's Law
Amdahl's Law(翻译成阿姆达尔定律)是一个公式,用来衡量并行度增加时,整个系统理论上的加速比。
定律内容
它的出发点很朴素,一个系统中有可以并行执行的部分和只能串行的部分(我们记为F),当系统的并行度增加时,只有可以并行执行的部分才能被加速,于是整个系统的加速比(并行度增加前的时间/增加后的时间)为:
$$ speedup \le \frac{1}{F + \frac{(1-F)}{N}} $$
其中 N 为并行度,可以理解成有 N 个 CPU。公式本身不难理解,分母是 1 表示加速前的时间,分子表示加速后的时间。串行部分 F 不受加速影响,保持不变,并行部分 1-F 所需时间变成 1/N,因此总和为 F + (1-F)/N。
我们画出并行度与加速比在一些串行比例下的关系:

可以看到串行部分的比例极大地影响了加速的效果,例如串行部分占 10% 时,并行度为 100,整体的加速比都不到 10%。换句话说你加了 100 个 CPU,换回了不到 10% 的性能提升。
我们可以从 Amdahl 定律中得到这样的推论:锁的粒度越细,并行度增加对系统的提速越明显。
锁的粒度
从 Amdahl 定律中我们知道,要提高系统理论的加速比,就要减少系统中串行的部分。当然,所有的性能优化,都应该以测试(Profiling)为基准。不过宏观上,我们知道 Java 中要保证线程安全,是需要通过加锁1来实现的,加了锁的代码能保证是“原子的”,换句话说,是“串行的”。
因此,从原理上,为了提高 Java 程度的理论加速比,我们需要减少串行的部分,也即减小锁的粒度。例如加在方法上的 synchronized 只加在需要同步的代码块上。
只不过一切都是权衡,为了提升性能,减小锁的粒度,通常代码就会变得更难理解,更难以维护2,更容易出错。有时候优化措施会需要打破系统的边界,例如需要在两个子系统间共享内存等。
因此通常情况下,不要盲目写一些“聪明”的代码(例如能用 synchronized 就不要用
ReentrantLock 之类的方法),一切以性能测试为基础。
增加并行度也有副作用
Amdahl 定律代表的是理论情况,因此理论上即使加速增加不多,增加并行度对整体性能还是会有提升。不过现实中,可能会是下面这样的曲线:

随着并行度的增加,加速比可能不升反降,这是因为并行度的增加很可能还会增加串行部分的比例。例如 JUC 中的一些类,尝试获得“锁”时,使用的是 CAS(Compare and Swap) 加上自旋(Spinning)等待的技术。在小并发度时,CAS 通常能很快成功,但在大的并发度下,CAS 经常性失败,自旋重试导致需要花费比原先更多的时间。
小结
Amdahl 定律告诉了我们系统整体可能的加速比受限于系统中的串行部分。在 Java 中,减少锁的持有时间,减小锁的粒度,都能有效减少系统中的串行部分,代价是代码更难理解、更难维护、更容易出错。
现实中单纯增加并发度还可能造成额外的性能损耗,因此并不是并行度越高越好。
另外,通常减少串行比例需要结合具体业务才能做到,后面的章节中会介绍利用 JUC 减小锁粒度的相关内容,但在此之前,我们会回归到 Java 线程,来看看使用线程实现并发需要付出的代价
严格来说,诸如 JUC 原子类的一些线程安全类使用的是 CAS 技术,也被称为“无锁”技术,这里我们不区分这些,统称“锁”。
还记得之前我们讨论 JUC 包时,说过 JUC 诞生的原因就是 Java 的内置锁不方便细粒度控制吗?
线程的代价
在 Java 中使用线程,通常不鼓励直接创建线程,而推荐使用线程池。在《Java 并发编程实战》的第 6 章中提到这几个问题:
- 线程生命周期的开销高。如线程的创建和销毁,需要操作系统辅助
- 资源消耗。大量如空闲的线程会占用内存,大量线程竞争 CPU 时会有额外开销
- 稳定性。通常操作系统限制了一些资源,如最大线程数,线程的栈大小等。过多线程会可能会出错
本章我们来具体聊一聊这些代价有多大。我们会尽量给一些量化的结论,但不要太过绝对化,生产中还要以实际的性能测试结果为准。
线程创建
在 Java 中创建一个线程分为两步:
Thread thread = new Thread(() -> ...);
thread.start();
其中 new 操作只是调用了 Thread::init 方法做了一些初始化的操作,此时还没有跟操作系统交互。Java 的线程是直接与操作系统线程是 1:1 的,在 Thread::start
时会调用操作系统的 API 创建 native thread(例如 Linux 下会调用 glibc 的
pthread_create 创建)。
我们用 JMH 框架做了一个简单的测试,测试代码如下:
@BenchmarkMode({Mode.AverageTime})
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@State(Scope.Benchmark)
@Warmup(iterations = 3)
public class MyBenchmark {
@Param({"1000", "2000", "3000"})
private int numThreadsToCreate;
@Benchmark
public void threadCreation(Blackhole bh) throws InterruptedException {
List<Thread> threads = new ArrayList<>(numThreadsToCreate);
for (int i = 0; i < numThreadsToCreate; i++) {
threads.add(new Thread(() -> bh.consume(1)));
}
bh.consume(threads);
for (Thread thread : threads) {
thread.start();
}
for (Thread thread : threads) {
thread.join();
}
}
}
最终的得到的结果:
new Thread大概是每个线程2usThread::start大概每个线程70us
换句话说,每秒可以创建约 1.4w 个线程,对于通常的使用来说,绝对是够用的。
内存消耗
Java(操作系统)会为每个线程的堆栈分配内存,线程一天不退出,内存一天就不释放(注意栈的内存属于“堆外内存”)。
Java 中可以通过 -Xss 来设置,在调用诸如 pthread_create 等方法时,JVM 会将
Xss 的值作为参数,决定了创建线程的栈空间大小,默认是 1024KB。那么理论上,你创建了 1000 个线程,就占用了约 1G 的内存,是很可怕的。
不过,操作系统有个机制叫作“虚拟内存”,如果只是申请内存,那么操作系统只分配了虚拟内存(可以理解为只做登记),只有当真正去访问这些内存时,操作系统才会将虚拟内内存映射到物理内存上,才真正消耗物理内存。
当然,如果是在 32 位机器上,虚拟内存的空间也只有 4G,如果申请的虚拟内存用完,程序也申请不到更多的内存了。但是现在几乎是 64 位的机器,不需要担心虚拟内存被分配完的情况。
因此:除非线程栈真的被使用了,否则几乎不占用物理内存。
那么如何验证上面的信息呢?首先我们可以通过下面命令,在 Java 程序结束后打印内存使用情况1:
- 启动程序时加上参数
-XX:NativeMemoryTracking=summary - 等命令启动后使用
jcmd <pid> VM.native_memory summary查看内存详情 - 也可以通过
XX:+UnlockDiagnosticVMOptions -XX:NativeMemoryTracking=summary -XX:+PrintNMTStatistics在程序结束后打印相关信息
如何,我们创建 1000 个线程,线程启动后 sleep 100s。
Java Heap (reserved=4194304KB, committed=262144KB)
(mmap: reserved=4194304KB, committed=262144KB)
Class (reserved=1066165KB, committed=14261KB)
(classes #590)
(malloc=9397KB #1569)
(mmap: reserved=1056768KB, committed=4864KB)
Thread (reserved=1048931KB, committed=1048931KB)
(thread #1021) # <- 创建了 1000+ 线程
(stack: reserved=1044480KB, committed=1044480KB) # 占用了 1020M 虚拟内存
(malloc=3256KB #5110)
(arena=1195KB #2040)
...
含义如下:
thread #1021表示创建了 1021 个线程reserved=1044480KB代表保留了内存,如启动参数-Xms100m -Xmx1000m,则 Heap 的 reserved 会对应 1000mcommitted=1048931KB代表真正分配的虚拟内存(malloc/mmap),但注意不代表真正占用的物理内存
那么如何确认实际占用的物理内存呢?在 MacOS 下可以使用 vmmap <pid>,Linux 下使用 pmap <pid> 来查看,这里以 vmmap 的输出为例:
REGION TYPE START - END [ VSIZE RSDNT DIRTY SWAP] PRT/MAX SHRMOD PURGE REGION DETAIL
...
Stack 000070000d532000-000070000d5b4000 [ 520K 36K 36K 0K] rw-/rwx SM=PRV thread 1
Stack 000070000d5b8000-000070000d6b7000 [ 1020K 108K 108K 0K] rw-/rwx SM=ZER thread 2
Stack 000070000d6b8000-000070000d7ba000 [ 1032K 8K 8K 0K] rw-/rwx SM=PRV thread 3
Stack 000070000d7bb000-000070000d8bd000 [ 1032K 8K 8K 0K] rw-/rwx SM=PRV thread 4
Stack 000070000d8be000-000070000d9c0000 [ 1032K 8K 8K 0K] rw-/rwx SM=PRV thread 5
...
Stack 000070003b540000-000070003b63f000 [ 1020K 12K 12K 0K] rw-/rwx SM=ZER thread 729
Stack 000070003b643000-000070003b742000 [ 1020K 12K 12K 0K] rw-/rwx SM=ZER thread 730
Stack 000070003b746000-000070003b845000 [ 1020K 12K 12K 0K] rw-/rwx SM=ZER thread 731
...
从 REGION TYPE 和 DETAIL 列可以得知这些是为线程分配的栈空间,其中的 VSIZE 代表虚拟内存,RSDNT 代表驻留内存(物理内存)。可以看到大概分配了 1020K 虚拟内存,但实际占用只有 12K。
同样的,除非有特殊需求,否则其实日常使用中,线程实际上占不了多少内存。
线程切换
在并发编程里,线程切换的开销也是常常提到的一个。线程切换(Context Switching),也叫上下文切换,指的是操作系统在中断线程运行时保存线程的上下文信息,之后恢复运行时再恢复上下文信息的操作。一般有这么几种情形:
- 多任务:例如线程运行时间太长被操作系统抢占,或线程调用了阻塞方法,主动暂停等。
- 处理中断信号:如我们敲了键盘,从硬盘读取的数据准备就绪等,一般发生在操作系统底层。
- 用户态与内核态的切换:当操作系统在用户态与内核态切换时(如调用
read读取数据),可能需要线程切换。
当许多线程长时间运行时,不可避免地会发生一些线程切换操作,由于 CPU 数量有限,通常线程越多,发生的切换也越多。类比的话可以理解成开车,由于道路拥堵,每辆车都走走停停,花费了更多的时间。
问题在于,一次线程切换的开销是多少?准确的测试需要很多细节的把控,这里引用文章 Measuring context switching and memory overheads for Linux threads 的结论:
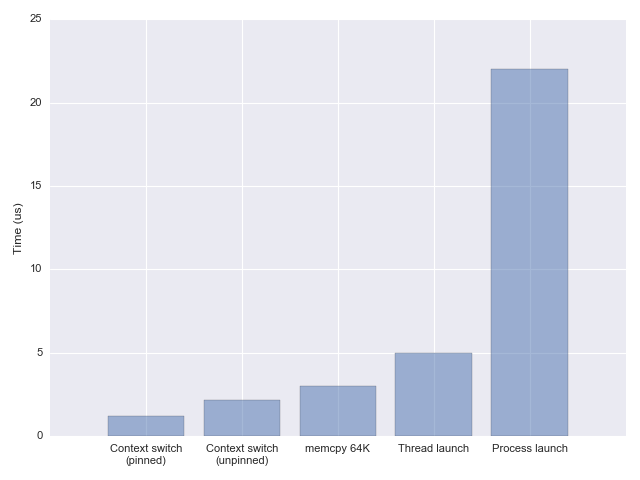
换言之,操作系统层面,一次线程切换大概需要 1~2us。日常情景下也是可以忽略的。
(如果想观察线程切换的频率,可以通过 vmstat 查看系统全局的切换情况,或用
pidstat -wt -p <pid> 查看某个进程的所有线程的切换情况)
开销之外
要注意的是,性能测试程序往往太片面,无法准确反映所有情况下的开销,所以正确看待上面结果的方式是:对开销的数量级有概念,不要过分迷信数字本身。实际编码时要以程序本身的性能测试结果为准。
同时我们也看到,绝大多数情况下,线程创建的开销、线程的内存占用及线程切换等开销都不太会成为瓶颈。因此虽然“线程池”技术本身的确能减少一些开销,但在我看来这并不能成为使用线程池的主要理由。
如果我们仔细挖掘,会发现我们使用线程执行任务,初衷是要并行执行任务,但是如果任务多了,我们其实有一些衍生的管理、编排的需求,例如:
- 顺序管理。任务按照什么顺序执行?(FIFO、LIFO、优先级)?
- 资源管理。同时有多少任务能并发执行?允许有多少任务等待?
- 错误处理。如果负载过多,需要取消任务,应该选哪个?如何通知该任务?
- 生命周期管理。如何在线程开始或结束时做一些操作?
上面列举的只是能想到的部分需求。其实推而广之,通常开始时我们只关注“任务”本身,但量变引起质变,数量多了,相应的会衍生出许多的管理、编排的需求。我们看到 Hadoop/Spark 会有资源管理、任务队列、错误记录等管理需求;微服务多了,我们也会需要像 Kubernetes 这样的容器编排工具做相应的管理。
在 Java 并发中,答案是“线程池”,即使无关乎开销,它也是必需品。
小结
本节中,我们对线程的一些开销做了量化:
- 创建、启动线程,约
70~80us - 内存占用,由于虚拟内存的机制,会按需占用物理内存,实验中看到初始占用
10~20K。 - 线程切换,引用了其它文章的数据,每次约
1~2us
再次强调这些具体的数字只做参考,关注数量级即可,实际要以程序的性能测试为准。
结论是,绝大多数情况下,这些开销都是微乎其微的,在性能测试前是不应该考虑的因素,也不应该是我们使用“线程池”的理由。使用线程池,更应该看重的是它的管理、编排的能力。这也是并发任务的量变引起的质变需求。
线程池
线程池(Thread Pool)主要承载了两方面的需求:
- 减少线程开销,同时避免创建过多线程
- 方便对线程、任务进行管理
线程池的背后是“池化”( Pooling)的思想。池化的想法是将常用的资源放入一个“池子”中,需要时从池子中申请,结束后返回给池子,池子里的资源被重复共享利用,能省去许多资源的创建和回收的消耗。同时由于资源被集中起来,也方便进行统一管理,如创建、分配、回收等。类似的应用还有连接池( Connection Pool)、内存池(Memory Pool)及对象池(Object Pool)等。
池化的实现整体上需要这样的结构:

如上图,资源池运作需要这样一些角色和过程:
- Request Queue(请求队列)。需要有一个队列来缓冲收到的请求
- 新的请求到来时,根据请求队列是否已满,选择接受或拒绝请求
- Resource Pool(资源池)。需要有一个“池子”来保存资源
- 资源不足时,可能向某个资源工厂申请创建新的资源
- 通常资源池中只保留一定数量的资源,当资源不再需要时,则销毁资源
- Coordinator(协调者)一般会有一个协调的策略,决定如何为请求分配资源
- 当请求的资源使用结束后,会将资源返还给资源池
- 创建和销毁也会有相应的策略
下面我们来看看,Java 中的线程池是如何设计的,和这个基本结构有哪些异同点。
线程池相关概念
我们希望使用线程池,将任务的提交和任务的执行解耦开来。在整体生命周期中我们会遇到下面几类概念,Java 中抽象了相应的接口:
- 任务本身
Runnable代表一个可执行的类,没有返回值,不可抛(受检查)异常Callable<V>,与Runnable类似,但有返回结果,可抛(受检查)异常
- 任务(异步)执行的结果
Future,可用来检查任务是否执行完成,完成时可获取结果,错误时可获取异常
- 任务的管理
Executor,单纯用来执行RunnableExecutorService,继承了Executor,提供了管理 API,可返回Future作为结果
以上提到的都是接口,都是抽象的概念,代表了 Java 内部是怎么看待线程池的功能的,内置的线程池都实现了 ExecutorService。本节会来聊一聊这些概念。
Runnable 与 Thread
如果我们翻阅 JDK 的文档,会发现 Runnable 和 Thread 是 JDK 1.0 就存在的,而其它的接口/类大多是 JDK 1.5 时和 JUC 包一起引入的。这也意味着 Runnable才是
Java 对“任务”最初的抽象。它的定义如下:
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
Runnable 的抽象概念就是“可以运行”的代码。只有一个 run 方法指定运行逻辑,没有返回值,也没有抛受检查异常(Checked Exception)。
Runnable 设计上是与 Thread.start 一起使用的。当一个类实现了Runnable 接口,我们就可以用它来创建一个线程,启动线程就会调用类的 run 方法。而 run 方法里想执行什么内容都可以。
Executor
Runnable 代表了任务本身,而 Executor 接口则定义了线程池的最简单行为:执行任务:
public interface Executor {
void execute(Runnable command);
}
Executor 接口十分简单,它只是定义了一个新角色:执行器,它唯一职责是执行任务。至于任务是同步执行还是异步执行,是创建新线程、用线程池还是直接在当前线程上运行,都没有规定。
尽管简单,Executor 还是从概念上将任务的提交和任务的执行解耦开了。用 new Thread(..).start() 方法时,任务的提交(通过 new Thread(..))与任务的执行
(Thread.start) 是绑定的,任务只能提交给新的线程,只能由该线程执行,只能在调用 start 时执行。而如果使用 Executor 的方式提交任务,就不会有这个问题。
ExecutorService 与生命周期管理
Executor 没有规定必须用线程池来执行任务,但如果我们真的使用线程池,就会立马发现 Executor 接口上的薄弱:
- 如何关闭?JVM 只有在所有(非守护)线程关闭后才会退出,我们需要关闭线程池的手段。
- 关闭时如何处理还在运行以及未运行的任务?
- 例如是立刻杀死还在运行的任务?还是等任务运行结束?
- 还在排队的任务是等运行结束?还是直接丢弃?还是需要返回给调用方?
- 关闭时如何处理新到来的请求?
为了满足生命周期的管理需求,ExecutorService 继承了 Executor 并扩展了如下方法:
public interface ExecutorService extends Executor {
void shutdown();
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
//...
}
除了无需多言的运行中(Running)状态,ExecutorService 又定义了关闭(Shutdown
)、终止(Terminate)两个状态1。具体的语义在 JDK 文档中有详细说明,这里简要说明如下:
shutdown时不接收新的请求,会等待正在运行和排队的任务完成shutdownNow时不接收新的请求,不处理等待的任务,会中断正在运行的任务
有了这些方法,我们就能更精细地管理线程池本身的生命周期。也因此在日常使用中,我们几乎不会直接使用 Executor 接口,且 JUC 中的线程池也都实现了
ExecutorService 接口。
Callable 与 Future
Runnable 不返回结果也不能抛出受检异常,如果我们关心执行的结果,要如何获取?简单粗暴的方法是使用共享的全局变量传递信息,如:
ExecutorService executorService = Executors.newFixedThreadPool(10);
AtomicInteger result = new AtomicInteger(0);
executorService.execute(() -> {
// with some complex calculation
result.set(10);
});
这里我们用 Java 8 的 Lambda 语法构造了一个 Runnable 对象,在执行结束时将计算的结果设置到共享的变量 result 中,以此来获取任务的结果信息。
不过这样做太绕了,于是 JDK 1.5 中又新增了 Callable 来表示一个会返回结果的任务,用 Future 接口表表示返回的结果。我们先来看 Callable:
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}
与 Runnable 不同的是 call 方法能返回结果,结果用泛型定义,并且抛出了受检查异常。
仅仅有任务的接口还不够,还需要有执行器的相关接口,在 ExecutorService 中定义了如下方法:
public interface ExecutorService extends Executor {
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException;
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
}
方法分成两组, submit 用来处理单个任务,invoke 用来处理多个任务。注意到
submit 方法接收 Callable<T>,并返回 Future<T>,当我们需要提交一个任务,并关心任务的返回结果时,就应该使用这个方法。于是刚才的需求就可以这么写:
ExecutorService executorService = Executors.newFixedThreadPool(10);
Future<Integer> result = executorService.submit(() -> {
// with some complex calculation
return 10;
});
那么这里返回的 Future 是什么呢?当我们提交一个任务时,并不会在 submit 等待,直到结果返回,而是 submit 后先执行后续的操作,由线程池慢慢执行任务。换句话说,任务的执行是异步的。
于是,在 submit 方法返回时,其实任务的结果还未就绪,接口 Future 要表达的就是这样的概念。Future 里最终会有结果(成功有值,失败有异常),但不一定现在就有,它的方法如下:
public interface Future<V> {
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
}
结果并不是马上就绪,因此提供了(非阻塞的) isDone 方法来检查任务是否结束(不管成功还是失败),两个 get 方法则是阻塞地等待任务结束,并返回结果(可能是正常结果,也可能是异常)。
cancel 方法则与任务的取消和关闭有关,后续章节会介绍。
有了 Callable、Future 以及 submit 方法,我们也能方便地表达提交任务到线程池,并期待任务返回结果的需求了。
小结
想要融入环境先要学会它们的语言,而 Java 中语言通常由接口描述。
本节中我们看到使用 Runnable 和 Callable 分别表示无返回和有返回的任务,由
Future 代表的异步返回结果,由Executor 代表的抽象执行器,由
ExecutorService 代表的带有生命周期管理的执行器。
Java 中的线程池使用围绕这些概念构建,最后我们也大概了解了一些 JDK 里自带的线程池实现,不同实现的主要区别是线程池内部管理策略的不同。
从这些接口的演变我们也可以窥探 Java 的蓬勃发展,JDK 1.0 中只有 Runnable 和线程的简单抽象,到 JDK 1.5 中对 ExecutorService 的解耦和抽象,再到 JDK 1.8 中实现 ForkJoinPool 来满足更高并发的需求。可以看到 Java 的应用场景和问题规模都在不断变大。
本节中我们主要讲解了线程池的概念,下节中我们会回到任务本身,关注如何取消或关闭一个任务。
如 ThreadPoolExecutor 内部还有更多的状态:RUNNING,
SHUTDOWN, STOP, TIDYING, TERMINATED,只是从接口层面只有 shutdown
和 terminated 两种
预定义线程池
前面的章节中我们介绍了“池化”的思想和基本结构,以及 Java中对线程池操作的抽象概念,并没有介绍线程池的实现。这个小节中,我们会介绍 JUC 的 Executors 类中预定义的一些线程池实现。
ThreadPoolExecutor
正确实现线程池的难度是非常大的,Java 中的线程池通常是基于 ThreadPoolExecutor
构建的,要么通过构造函数来改变行为,要么通过继承它来扩展行为。我们先来看看它的构造函数:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
// ...
}
我们看到,多数概念跟我们之前提到的“池化”的基本结构是对应的:

各个参数也可以在图中找到直接的对应关系:
corePoolSize,线程池中线程的保底数量,新来任务时会创建线程,直到达到corePoolSize数量maximumPoolSize,队列满时,会创建新线程,该参数决定允许创建的最大的线程数keepAliveTime,多出保底线程数的线程不用时需要被销毁,该参数表示最大空闲等待时间unit,等待时间的单位workQueue,提交任务的等待队列threadFactory,创建新线程时使用的工厂实例,可定制名称,UncaughtExceptionHandler等。handler,workQueue 满时,会拒绝新的任务,handler用来决定如何拒绝。
Executors 工厂类
那么 Executors 中提供了哪些预设的线程池呢?
-
newFixedThreadPool,创建固定线程数的线程池,新任务提交时,线程池会不断创建新的线程,直到达到设定的最大值,其后不创建也不销毁线程,如果线程意外退出,会再创建新线程直到最大值。public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); } -
newSingleThreadExecutor,创建只有单个线程的线程池,所以实际上提交到这个线程池的任务并不会并发运行。public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); } -
newCachedThreadPool,创建可缓存的线程池,当任务多于当前线程,则会创建新的线程用于执行任务,当线程空闲时会被回收,创建的线程数不受限制。public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
除此之外,Executors 还提供一些基于其它线程池实现的预设线程池:
newScheduledThreadPool,创建固定大小的线程池,提交的任务可以指定以延迟或定时的方式运行,严格来说它返回的是ScheduledExecutorService,虽然这个接口也继承了ExecutorServicenewSingleThreadScheduledExecutor与newScheduledThreadPool类似,只是线程池中只有单个线程。newWorkStealingPool构造工作窃取队列,是 JDK 1.8 新增的方法,基于 JDK 1.7 增加的ForkJoinPool实现,内部会使用多个工作队列来降低对队列的竞争,队列大小无上限。
不过,注意到 Executors 创建的线程池使用的都是无界的队列,会有潜在过载导致
OOM 的问题,通常建议使用有界队列(但是最好搞清楚它们的差异)。另外,如果使用
Spring 框架,建议使用它的 TaskExecutor 抽象,使用 TaskExecutorBuilder 创建线程池,更方便定制。
小结
本节主要介绍了 ThreadPoolExecutor 的基本结构和参数,并介绍了 Executors 提供的一些预定义的方法。一方面可以直接使用,另一方面也方便了解一些常用的线程池需求如何实现。
当然,这里只是介绍如何创建,但是创建时要用什么参数就是门学问了,下节会介绍一些常见的注意事项,更多时候还是需要掌握基本原理,具体问题具体分析。
线程池使用
上节中我们了解了线程池的一些基本概念,线程池在使用上还有一些需要注意的地方。
线程池大小
先上结论:没有标准方法能完美决定线程池的大小,需要测试,具体问题具体分析。
这里摘抄文章Java线程池实现原理及其在美团业务中的实践中的调研结果:
| 方案 | 问题 |
|---|---|
| $$N_{cpu} = \text{number of CPUs}$$ $$U_{cpu} = \text{target CPU utilization}, 0 \le U_{cpu} \le 1$$ $$\frac{W}{C} = \text{ratio of wait time to compute time}$$ $$N_{threads} = N_{cpu} U_{cpu} (1 + \frac{W}{C})$$ | 出自《Java 并发编程实战》,方案偏理论,像线程的计算时间和等待时间很难测算 |
| $$coreSize = 2 N_{cpu}$$ $$maxSize = 25 * N_{cpu}$$ | 没有考虑使用多个线程池的情况,且统一配置明显不符合多样的业务场景 |
| $$coreSize = tps \times time$$ $$maxSize = tps \times time \times (1.7 \text{~} 2) $$ | 考虑了业务场景,但假定流量平均分布,可能不符合实际业务场景 |
可以将上面的公式作为一个经验数值,再根据实际的业务情况来做性能测试来微调。就像美团的文章里说的,很多时候,流量的压力并不是平均的,实际上也不可能有一套参数能解决所有问题,还是得具体问题具体分析。
有界还是无界
阿里的 Java 规范里有这么一条:
【强制】线程池不允许使用
Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
原因是 Executors 方法创建出的线程池,全都是无界队列,这样的队列会一直接收任务,直到内存耗尽(OOM)1。如果有界队列满了,
ThreadPoolExecutor 默认会抛出 RejectedExecutionException 异常。一个常见的需求是如果队列满了,就阻塞提交任务,可以这么实现:
ExecutorService pool =
new ThreadPoolExecutor(
2, // corePoolSize
4, // maximumPoolSize
60, // keepAliveTime
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(10), // ① bounded queue (capacity = 10)
(r, e) -> {
try {
e.getQueue().put(r); // ② on Rejected, blocking put
} catch (InterruptedException interruptedException) {
interruptedException.printStackTrace(); // ③ print and abort on interrupted
}
});
在 ① 处定义了接收线程池任务的有界队列,大小为 10,当等待任务超过 10 个时,新任务会在 ② 处调用阻塞的 put 方法再次提交到队列中直到队列能容纳新的任务。在 ③
中处理提交被中断时的情形。
阿里的规范里并不要求一定要创建有界队列,很多时候需要具体问题具体分析,不过个人认为有界队列通常是更好的选择,毕竟系统压力大时,本身就处理不了那么多任务,无界队列不断堆积任务,不仅处理不了,还消耗额外的内存,作用不大。
饱和策略
在使用有界队列时,当提交的任务达到了队列的上限,此时应该如何处理?处理的策略就称作饱和策略(Saturation Policies)。上节中我们自定义了策略:阻塞提交到队列中。ThreadPoolExecutor 提供了一些策略方便使用,它们实现了RejectedExecutionHandler:
AbortPolicy:拒绝新的任务,抛出RejectedExecutionException异常DiscardPolicy:默默抛弃新的任务,不抛异常DiscardOldestPolicy:抛弃队列中最老的未被处理的任务,并尝试重新提交新任务CallerRunsPolicy:在调用方的线程上运行新任务
ThreadPoolExecutor 默认使用 AbortPolicy:
private static final RejectedExecutionHandler defaultHandler = new AbortPolicy();
饥饿死锁
一般死锁的发生都是由于出现了循环依赖,考虑任务 A 依赖了任务 B、C 的结果,假设 A 将任务 B、C 提交到同一个线程池,那么可能发生下面的情形:

问题在于,在 B、C 任务执行完成前,任务 A 所在的线程会一直被占用。如果线程池中有空闲的线程,则 B、C 任务最终会被执行,从而任务 A 最终完成(图中上面的情况)。但是如果此时有两个任务 A 占用了线程池,导致提交的 B、C 任务无法执行,此时产生死锁(图中下面的情况)。
原因是任务 A 依赖 B、C 的结果,而 B、C 又依赖任务 A 退出释放线程资源。
只运行独立同构任务
同一个线程池中运行异构的任务,除了上面说的死锁的问题,还可能影响响应时间。
例如有一些时间敏感的任务,和一些时长很长的任务一起提交到线程池中,可能出现大量线程被时长很长的任务占据,导致时间敏感的任务需要等待很长时间才能被运行,从而导致响应时间过长。
所以推荐在线程池中只运行同构的任务,同时为了防止死锁,尽量运行独立的任务。
扩展 ThreadPoolExecutor
要正确实现一个完整的线程池是非常困难的,很多时候我们只是希望增加某个功能或对现有功能做微调。一种方式是构造 ThreadPoolExecutor 时使用不同的参数;另一种是直接继承 ThreadPoolExecutor。
ThreadPoolExecutor 有 3 个 protected 函数可供扩展:
beforeExecute:在任务被执行前执行,可以用来增加一些监控信息。如果方法抛异常,则任务不被执行,且相应的afterExecute不被执行。afterExecute:在任务执行结束后执行,由任务的执行线程调用。terminated:线程池中止后执行。可以用来释放线程池分配的资源、记日志等。
注意的是,实现这些方法时,约定上需要调用 super 的相应方法。
例如我们希望记录线程池所有线程总的运行时间,可以这样做2:
public static class TimingPool extends ThreadPoolExecutor {
private final ThreadLocal<Long> startTime = new ThreadLocal<>();
private final AtomicLong totalTime = new AtomicLong(0);
private final Logger log = Logger.getLogger("TimingPool");
public TimingPool(int corePoolSize, int maximumPoolSize, long keepAliveTime,
TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
protected void beforeExecute(Thread t, Runnable r) {
startTime.set(System.currentTimeMillis());
super.beforeExecute(t, r);
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
long elapsed = System.currentTimeMillis() - startTime.get();
totalTime.addAndGet(elapsed);
super.afterExecute(r, t);
}
@Override
protected void terminated() {
log.info("total time(ms) is: " + totalTime.get());
super.terminated();
}
}
小结
线程池只是一把剑,有了剑还得修炼剑法才能成为大侠。本节介绍了使用线程池的一些注意点,包括线程池大小的确定;队列应该有界还是无界;队列满了该怎么办;极端情况下的饥饿死锁问题;以及如何扩展线程池的行为。
这些内容只能是算抛砖引玉,希望读者能查阅更多资料,在实际中掌握更多线程池的使用技巧,也欢迎探讨这里没有涉及的内容。
线程池的使用已经很复杂了,线程的清理可能还更复杂一些,下面的小节中我们会开始介绍线程的关闭及线程池的关闭。
我们希望在消费有压力的时候,能给上游的生产方压力,这也叫做“背压”(backpressure),在线程池里,通过创建有界的队列,在队列满时会抛出异常,能及时给上游反馈,希望能减少生产的速率。
修改自《Java 并发编程实战》
线程的中断
当一个任务在线程里执行时,要如何停止这个任务/线程?中止一个线程有涉及诸多问题,例如:
- 如果线程里加锁了,此时突然中止线程,谁来释放锁?
- 如果线程里打开了一个文件,中止线程,谁来关闭文件?
- 如果业务上要求做两个操作,只做了一个就中止了线程,如何保证逻辑正确?
单方面中止线程,不再执行线程的后续操作是十分危险的,也因此几乎没有任何编程语言提供了单方面中止线程的能力1。显然 Java 也没有提供直接中止线程的机制,那么我们要怎么停止任务?
轮询与中断
轮询和中断这两个概念会不断出现在编程世界中(甚至是现实世界中)。
- 轮询指隔段时间检查一下。好比每分钟检查下烧的水开了没
- 中断指事件发生时通知。比如在写文章的时候,水壶响了,中断了当前的工作,去处理烧开的水。
这里的中断蕴含了“抢占”的要求,水烧开了就必须立马响应,不能等写完文章再处理,我们上面说过为线程提供“中断”功能是很危险的,那如果只使用“轮询”,要怎么实现关闭呢?其实很简单:
public class Searcher {
private volatile boolean cancelled; // ①
public List<String> searchWith(String keyword) {
List<String> results = new ArrayList<>();
while (!cancelled) { // ②
String nextCandidate = getNextCandidate();
if (match(nextCandidate, keyword)) {
results.add(nextCandidate);
}
}
return results;
}
public void cancel() {
this.cancelled = true; // ③
}
}
在 ① 处设置一个取消的标志位,在任务执行期间(②)不断轮询标志位的值,如果设置了则退出,而提供的取消方法(③)只需要设置标志位即可。需要注意的是标志位需要正确同步,比如例子中使用了 volatile,也可以使用 AtomicBoolean。
轮询很多时候只是无奈之举,它并不理想:
- 响应不及时。如果业务逻辑运行时间长(如上例的
match函数),则在一次match结束前searchWith是不会检查cancelled的状态的。 - 额外开销。一方面检查标志位有开销(虽然不大),另一方面任务必须定期检查标志位,不能阻塞。例如等待 socket 的数据,必须在等待时设置超时并定期检查标志位,即使没有数据也不能阻塞。
- 额外的编码。处理退出的逻辑需要嵌入业务逻辑中,影响代码整洁。
所以从编码体验上来说,通常希望直接调用阻塞(blocking)方法,并在想取消时,能够用中断的方式唤醒线程。那么 Java 是如何解决这个问题的?
Java 中的伪中断
在很多语言中,轮询是唯一安全的取消任务的方法,但 Java 提供了伪线程“中断”机制,让我们能够唤醒很多阻塞方法(不是全部),方便地实现任务的取消。我们先来看看
Thread 提供的相关方法:
public class Thread implements Runnable {
public void interrupt() {...}
public static boolean interrupted() {...}
public boolean isInterrupted() {...}
}
Java 的每个线程中都会存储一个 boolean 类型的变量,来标识线程是否被中断。当我们调用了一个线程的 interrupt 方法时,JVM 会首先将该标志位设置成 true,再唤醒线程,JDK 的一些内置方法(如 Thread.sleep,ArrayBlockingQueue.take)被唤醒后,会检查线程是否被中断,并做出对应的操作,如抛出 InterruptedException异常。
interrupted() 与 isInterrupted() 函数被调用时都会返回线程“是否中断”的信息,不同的是 interrupted 函数还会清除中断标志位。一般来说,如果库函数在检测到中断时会抛出异常,那么抛出异常前一般会清除中断标志,反之不抛异常则需要保留标志让上层感知中断的发生。
那么在我们的业务代码里感知到了中断,要如何做相应的处理呢?
如何处理中断
首先要意识到“中断”的含义是,有其它线程不希望我们的任务继续运行下去,那么从遵守约定的角度出发,当我们检测到有中断发生时,应该尽快做好善后工作(如释放资源)并结束运行,同时要把中断的消息告知上游调用方。
接收异常一般有两种方式,一种是调用的库函数抛出了 InterruptedException,另一种是我们通过 isInterrupted 或 interrupted 检测到了有异常发生。同样的,在做好善后工作后,我们也可以尽量以这两种方式向上游传递中断。例如可以直接传递异常:
BlockingQueue<Task> queue;
...
public Task getNextTask() throws InterruptedException { // ①
return queue.take();
}
直接将 queue.take 的受检异常在 ① 处重新抛出。如果不想抛出异常,就要确保中断标志被正确设置,要注意到当 JDK 库方法抛 InterruptedException 异常时,通常会清除中断标志(内部调用了 interrupted)方法,因此我们可以再次调用
interrupt() 来重新设置中断标志:
public Task getNextTask(BlockingQueue<Task> queue) {
boolean interrupted = false;
try {
while (true) {
try {
return queue.take();
} catch (InterruptedException ex) { // ①
interrupted = true;
// retry
}
}
} finally {
if (interrupted) {
Thread.currentThread().interrupt(); // ②
}
}
}
上例中在 queue.take() 被中断时会抛出 InterruptedException 并清楚标志位,我们在 ① 处捕获并重试。即使重试成功返回,我们也应该告知调用方有中断发生,因为这意味着有其它线程希望我们尽快退出。于是我们在 ② 处调用 interrupt 方法重新设置中断标志位,这样如果调用方正确检测中断标志位,就能正确响应中断。
不可中断的阻塞
上面我们看到,Java 中的中断其实是不是真的“中断”,本质上还是“轮询”,只是多数的库阻塞函数,都遵守了检查中断标志的约定,能抛出异常提前返回。但并不是所有阻塞函数都能被中断。
上面我们说过,调用 interrupt 方法时,底层的原理是设置中断标志,并唤醒线程,这时一些库函数会检查中断标志,发现中断发生,清除中断标志,并抛出异常。具体来说,有这么几类:
- 如果阻塞在
Object.wait、Thread.join或Thread.sleep方法,则中断时会清除中断标志并抛出InterruptedException异常。 - 如果阻塞在
InterruptibleChannel的 I/O 方法,则在中断时会设置中断标志并抛ClosedByInterruptException异常。(多数标准 Channel 实现了该接口) - 如果阻塞在
Selector.select方法,中断时会设置中断标志并立即返回,效果类似于调用了wakeup方法。
不响应中断的阻塞方法有:
- Java.io 包中的同步 Socket I/O。如
InputStream/OutputStream的read/write方法不响应中断。想要中断只能关闭底层的 Socket,此时read/write方法抛出SocketException - 获取锁。如
synchronized和 JUC 中的Lock.lock都不响应中断,它们会被唤醒并尝试获取锁,失败后继续阻塞。有一个例外是 JUC 中的Lock.lockInterruptibly会响应中断并抛出InterruptedException,JUC 中响应中断的阻塞方法通常都是调用它来获取锁的。
Future 实现取消
上面的讨论中,我们的视角是被中断方,也就是线程或者任务本身,那么从中断方来说,我们应该调用 interrupt 方法吗?应该怎么调用?
这里的问题是我们想要结束是任务,但是我们的控制粒度是线程,但是线程有可能被用来运行其它任务,例如,我们希望在当前任务运行超时时杀死任务,一个实现方式是:
private static final ScheduledExecutorService cancelExec = ...
public static void timedRun(Runnable task, long timeout, TimeUnit unit) {
final Thread taskThread = Thread.currentThread();
cancelExec.schedule(() -> taskThread.interrupt(), timeout, unit); // ①
task.run(); // ②
}
我们在 ① 中将取消的任务提交到定时的线程池 cancelExec 中,预期是如果超时了,②
中的任务还在运行,则 ① 的 interrupt 会中断当前线程。但是,如果 interrupt
调用时 task.run 已经结束了呢?线程中运行着的可能是调用方的其它任务,也可能是线程池中提交的其它任务,不管哪种情形,此时调用 interrupt 都是不符合预期的。
还是那个问题,我们想停止的是任务,但是中断只能对线程使用。那么有办法针对任务进行中断吗?如果使用的是线程池的话,答案是 Future:
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
}
- 如果任务未运行,调用了
cancel方法后任务将不再会运行 - 如果任务在运行,则会根据参数
mayInterruptIfRunning来决定是否中断任务线程 - 如果任务运行结束,或已被取消,则方法返回
false,无作用
所以上面的需求可以这么实现:
public static void timedRun(Runnable task, long timeout, TimeUnit unit) {
Future<?> task = taskExec.submit(task);
try {
task.get(timeout, unit); // ①
} catch (TimeoutException e) {
// do nothing, wait for finally
} catch (ExecutionException e) {
throw ...
} finally {
task.cancel(true); // ②
}
}
① 中进行超时等待,并在 ② 中调用 cancel,且由于 cancel 是幂等的,即使正常返回也不影响。
小结
与其它编程语言一样,Java 没有提供抢占式的中断线程的方法,它基于轮询的方式,为常用的阻塞函数实现了“中断”的约定,一方面很多库函数会抛 InterruptedException
需要处理,很麻烦,另一方面它其实是一个相当灵活的中断机制。
中断的内部实现依赖了中断标志的设置与检查,业务代码在检测到中断的时应当尽快做好善后工作并通知调用方发生了中断,通常是传递下层抛的异常,或通过调用
Thread.interrupt 方法重新设置中断标志。
当然还有一些阻塞方法不会响应中断,对于 IO 操作可以尝试关闭数据源,对于锁可以考虑使用 Lock.lockInterruptibly,并没有通用的方法。
在使用中断时,我们发现调用 interrupt 来中断线程是相当危险的,如果任务是提交到线程池里,通常通过 Future.cancel 来取消任务会更安全。
中断是对单个线程/任务的取消(Cancel),下节中我们来谈谈线程池及 JVM 的关闭( Shutdown)操作。
参考
- 《Java 并发编程实战》第七章
- Java线程源码解析之interrupt 源码解析库函数阻塞方法如何响应中断
- 从AQS到futex(二): HotSpot的JavaThread和Parker JVM 底层的中断实现
- jvm源码分析之interrupt() 同样是源码分析
当然 C 语言提供的操作系统 API,是有对应方法的,但从编程语言的支持上,没有见过,我熟悉的 Java/Python/Rust 都是没有的,包括 Go 语言也无法强制中止 goroutine。
如何优雅退出
上节中我们讨论了如何中断一个线程,这节我们讨论如何关闭 JVM 进程。
如何关闭 JVM
关闭分为正常关闭和强制关闭。
触发正常关闭的方式有:当最后一个(非守护)线程退出结束时;调用了 System.exit
或 Runtime.exit 时;以及接收到操作系统的退出信号时(如收到
SIGINT 信号,或按了 Ctrl-C 发送了 SIGTERM 信号等)。
强制关闭可以通过调用 Runtime.halt 方法或通过操作系统发送 SIGKILL 信号(如通过 kill -9 <pid>)实现。
正常关闭与强制关闭的区别在于,正常关闭时,JVM 会调用 Shutdown Hook(关闭钩子),等到所有 hook 执行结束后再退出 JVM。因此在正常关闭的情况下,我们可以通过 Shutdown hook 机制在退出前做一些清理(如清理产生的临时文件,打印所有未打印的日志等),来实现“优雅退出”。
Shutdown Hook
Shutdown hook 需要通过 Runtime.addShutdownHook(Thread hook) 注册,我们把传入的线程称作 hook,addShutdownHook 要求 hook 线程尚未启动,且一个线程只能注册一次。Hook 的执行有两种情况:
- 正常情况下,需要等所有非守护线程退出,才开始执行
- 当 JVM 接到关闭信号(如
SIGINT)时执行,此时与非守护线程并发执行。
所有的 hook 线程在 JVM 正常退出时被一起启动,执行顺序没有保证。当所有 hook 线程结束时,JVM 将停止运行1,停止时并不会关闭或中断任何仍然在运行的应用程序线程。
由于 hook 线程在运行时仍然是并发的环境,要保证其中的逻辑是线程安全的。同时, hook 线程不应该对程序是如何结束的有任何假设(如某个服务是否已经关闭),因为任何情况都有可能发生。最后,和线程中断一样,hook 线程应该尽快退出,因为调用方预期 JVM 尽快结束。
通常会在 hook 线程中做一些资源清理的工作,来达到“优雅退出”的目标。例如 Spring
框架中,每个 ApplicationContext 需要实现 registerShutdownHook 方法来注册清理的逻辑,例如 AbstractApplicationContext 的实现如下,调用 doClose 来清理相关资源:
public void registerShutdownHook() {
if (this.shutdownHook == null) {
// No shutdown hook registered yet.
this.shutdownHook = new Thread(SHUTDOWN_HOOK_THREAD_NAME) {
@Override
public void run() {
synchronized (startupShutdownMonitor) {
doClose();
}
}
};
Runtime.getRuntime().addShutdownHook(this.shutdownHook);
}
}
建议用一个 hook 线程来做所有的关闭操作(如上面的代码),这样将所有的关闭操作串行执行,可以减少很多由并发带来的竞争和死锁问题,例如可以防止关闭某个服务时依赖了另一个服务,而它又被另一个 hook 线程关闭了而造成的死锁。
守护线程
守护线程(Daemon Thread)是在后台运行的低优先级的线程,当 JVM 正常退出时,会等待所有非守护线程退出后才退出,而不管守护线程的死活。
可以调用 Thread.isDaemon 来判断线程是否为守护线程,可以在线程启动前调用
Thread.setDaemon 来设置是否为守护线程。在一个线程中创建了另一个线程,是否守护的状态会被继承。JVM 启动时只有主线程是普通线程,其它都是守护线程,于是可以推论,默认情况下,主线程创建的所有线程都是普通线程。
一般不建议将线程设置成守护线程,因为守护线程的潜在约定是其它线程结束后,它可以随时被中止。而很少有线程能达到这个条件,例如线程中如果包含 I/O 操作,突然被中止而不做清理可能导致数据没有被正确写入,临时文件没有被清理等。还记得上节中提到语言层面不提供抢占式中断的原因吗?也同样是不建议使用守护线程的原因。
一些没有外部依赖的清理工作可以设置成守护线程,如系统 GC 线程,或是一些清除内内存缓存的线程。
关闭线程池
在系统退出前,需要手工关闭线程池,否则诸如 newFixedThreadPool 线程池会始终保持 N 个在运行的线程,从而阻止 JVM 正常退出。
我们知道 ExecutorService 有两个关闭方法,shutdown 会拒绝新的请求,并等待所有(在运行的和排队中的)任务退出;shutdownNow 会中断正在运行的任务,并返回所有还未运行的任务。当然,如果有任务不能正确响应中断(如在获取锁),那么没有通用的手段能强制它们退出。
shutdownNow 的局限在于没有通用方法处理在运行中的任务,需要从业务角度做处理。例如接收到中断时记录被取消的任务2:
static class TrackingExecutor extends AbstractExecutorService {
private final ExecutorService inner扩展
private final Set<Runnable> cancelledTasks = Collections.synchronizedSet(new HashSet<>());
//...
public List<Runnable> getCancelledTask() {
if (!isTerminated()) throw new IllegalStateException(...);
return new ArrayList<>(cancelledTasks);
}
@Override
public void execute(Runnable command) {
inner.execute(() -> {
try {
command.run();
} finally {
if (isShutdown() && Thread.currentThread().isInterrupted())
cancelledTasks.add(command);
}
});
}
}
这种方法可能有“误报”,有些任务可能运行结束,但在设置状态前,线程池被关闭了,于是也可能被包含在被取消任务中。当然,要如何处理被取消的任务需要根据业务情况具体分析,例如爬虫任务可能可以无脑重试(幂等),下定单任务可能要额外判断是否可重试了。
对于无法响应中断的任务,实现时需要准备一些额外中止手段,如任务执行逻辑轮询某个退出标志。
处理异常退出的线程
有些任务可能是同构的,如多个线程消费消息,处理逻辑相同;有些任务可能是异构的,如发送消息和接收消息就是不同的逻辑。
如果由于某些原因,某个线程异常退出了(如调用下游某个 API 时抛异常,且没有被捕获),JVM 会照常执行。如果退出的同构任务中的一个,风险还可控,如果退出的是某个异构任务,程序的整体逻辑就会有问题,如唯一的发送消息的任务异常退出,程序的正确性就有问题)。
最重要的解法还是要求程序正确编码。作为通用性的事后处理,一般至少要记日志,如果严重的还要对接一些监控告警的系统。从语言层面,提供了线程异常退出的通知机制,供用户自定义处理逻辑。
public interface UncaughtExceptionHandler {
void uncaughtException(Thread t, Throwable e);
}
调用 Thread.setDefaultUncaughtExceptionHandler 来设置线程的 Exception
Handler(异常处理程序),如果是需要为线程池中的 Handler,则需要在构造线程池时指定自定义的工厂函数,如:
ExecutorService pool = Executors.newCachedThreadPool((runnable) -> {
Thread thread = new Thread(runnable);
thread.setUncaughtExceptionHandler((t, e) -> System.out.println(...));
return thread;
});
另外注意一个线程中创建另一个线程,Exception Handler 是不继承的。
小结
何为“优雅”?正确地清理使用的资源即为优雅。JVM 正常退出时提供了 Shutdown hook机制让我们能在退出时执行自定义的清理逻辑,通常线程池的关闭逻辑我们也会放到这里。
正确关闭线程池并不容易,虽然我们有 shutdown 和 shutdownNow 两种关闭语义,过程中还是有一些未定义的任务需要处理:关闭时正在执行的任务。shutdownNow 会发送中断请求,但线程不一定能响应中断。而即使线程响应了中断,线程池也不会有额外的处理。通常后续的处理需要看业务上的需求。
此外,如果线程因为未捕获的异常而退出,根据任务的不同,可能会有严重的影响,Java
提供了 UncaughtExceptionHandler,用于注册异常退出时的处理逻辑,具体逻辑通常也依赖业务需求。
严格来说如果设置了 runFinalizersOnExit,还会运行所有对象的finalizer,现在已经不推荐使用这项技术了。
例子来源《Java 并发编程实战》
怎么看源码
我认为在看代码时需要注意下面 3 点:
- 业务需求:代码想要达到什么效果
- 技术设计:如何通过一些手段来达到目的,为什么用这种设计能达到目的
- 技术实现:实现细节上有哪些亮点
Unsafe
Just because you can break the rules, doesn’t mean you should break the rules—unless you have a good reason. -- Ben Evans
上层需求
sun.misc.Unsafe 是一个底层包,它的方法几乎都是 native 方法,提供了利用底层特性的能力,如使用 CPU 及其它硬件的特性的能力,绕过 JVM 对内存做特殊操作的能力等。强大的能力通常意味着巨大的风险,使用 Unsafe 极其容易出错,一般应用程序中也不应该使用。
由于 Unsafe 大多是 native 方法,所以只能看 openjdk 的 Unsafe.cpp。
获取实例
在 JUC 的代码中,常常会这么获取 Unsafe 的实例:
private static final Unsafe unsafe = Unsafe.getUnsafe();
如果复制这份代码尝试运行,发现会报 SecurityException,根本无法运行。这是因为
Unsafe 实在是太危险了,因此不允许在应用程序代码中使用,如果要使用,只能通过反射的方式获得实例:
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
return (Unsafe) f.get(null);
(另:JDK 1.9 中 Unsafe 类被移到 jdk.unsupported 模块,显然是不希望开发者继续使用,一些重要的功能通过 Variable
Handles 提供。)
Field Offset
第一个重要的概念是 Field Offset,即一个类中某个字段的偏移量,可以看到 Unsafe
中的方法在操作类中某个字段时,几乎都是直接操作字段在内存中的偏移量。
内存布局
类在内存中的结构 JVM 规范中并没有定义,这里以 HotSpot JVM 为例,它使用了 Ordinary Object Pointers(OOPS) 的数据结构1,我们不关心细节,只是有个大概的印象。
对于下面这个类:
public class SuperClass {
private int id;
private ZonedDateTime createTime;
}
public class SubClass extends SuperClass {
private boolean deleted;
private String content;
}
使用 jol-core 打印出类的内存布局(jol 只支持 HotSpot):
SubClass object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 4 int SuperClass.id N/A
16 4 java.time.ZonedDateTime SuperClass.createTime N/A
20 1 boolean SubClass.deleted N/A
21 1 boolean SubClass.valid N/A
22 2 (alignment/padding gap)
24 4 java.lang.String SubClass.content N/A
28 4 (loss due to the next object alignment)
Instance size: 32 bytes
Space losses: 2 bytes internal + 4 bytes external = 6 bytes total
我们大概需要知道:
- 包括父类继承的字段,都存放在同一片内存区域中
- Java object 有固定大小的 object header
- 字段为了对齐会加上 padding,这是 CPU 的限制,CPU 为了速度,取数时会对齐到
word 上。如上例
valid只占 1 个字节,后面有 2B 的 padding - 如果有多个小字段,为了减少对齐浪费的空间,会移动字段,如
valid被移到了deleted之后。
当然 JVM 还有其它一些机制,如压缩对象等会影响对象的内存结构,这里不细说。
objectFieldOffset
Unsafe.objectFieldOffset 可以用来获取字段的偏移量,不过文档里说明,获取的 offset 并不保证代表了字段的实际偏移量,而只是偏移量的代号。不过在 HotSpot 的实现中,我们看它实际上返回的就是偏移量的字节,我们可以验证一下:
Unsafe unsafe = getUnsafe();
System.out.println(unsafe.objectFieldOffset(SubClass.class.getDeclaredField("valid")));
// 21
看到 21 就是之前内存结构中 SubClass.valid 所在的偏移量。不过既然文档说了不保证 objectFieldOffset 返回的是偏移量,我们也不应该做这个假设。
字段的访问操作
大概有这么几类:
// 获取字段的值,类似的还有 getInt,getDouble,getLong,getChar 等
public native Object getObject(Object o, long offset);
// 设置字段的值,类似的还有 putInt,putDouble,putLong,putChar 等
public native void putObject(Object o, long offset, Object x);
// 获取字段的值,使用 volatile 语义,有 Int, Double, Long, Char 等变种
public native Object getObjectVolatile(Object o, long offset);
// 设置字段的值,使用 volatile 语义,有 Int, Double, Long, Char 等变种
public native void putObjectVolatile(Object o, long offset, Object x);
// putObjectVolatile 的变种,设置的值不保证被其他线程立即看到。
// 只有在 field 被 volatile 修饰符修饰时有效
public native void putOrderedObject(Object o, long offset, Object x);
其中 getXXX/putXXX 与 getXXXVolatile/setXXXVolatile 与 Java 中的赋值/取值的语义相同,唯一的不同是 Unsafe 中的方法直接操作内存,可以无视 Java 中的访问控制,即无视 private,protected 等修饰符。
putOrdered
putOrderedXXX 需要特殊说明,它是 JUC 中常用的方法,通常用来实现惰性赋值。例如需要将某个变量设置成 NULL 允许 GC 释放对应的内存。
putOrderedXXX 会保证同线程多次写入之间是有序的,但不保证写入的值立即对其它线程可见。这一区别使得它的性能比 putXXXVolatile 方法要高出不少。
更底层来看,putOrderedXXX 只需要使用 StoreStore 屏障来保证有序即可,这在多数的体系结构下不需要额外的操作或代价很低,而 volatile 写则需要 StoreLoad
屏障,而这个操作通常代价很高2。
开始看代码找到
unsafe.cpp
,却发现 putOrderedObject 的实现与 putObjectVolatile 一模一样。后来才发现内存屏障的区别是 JIT 期间优化的,在
LibraryCallKit::inline_unsafe_ordered_store
方法中实现,可以对比 volatile 变量写入的逻辑
LibraryCallKit::inline_unsafe_access
:
bool LibraryCallKit::inline_unsafe_ordered_store(BasicType type) {
// ...
insert_mem_bar(Op_MemBarRelease);
insert_mem_bar(Op_MemBarCPUOrder);
// Ensure that the store is atomic for longs:
const bool require_atomic_access = true;
Node* store;
if (type == T_OBJECT) // reference stores need a store barrier.
store = store_oop_to_unknown(control(), base, adr, adr_type, val, type);
else {
store = store_to_memory(control(), adr, val, type, adr_type, require_atomic_access);
}
insert_mem_bar(Op_MemBarCPUOrder);
return true;
}
---------------------------------------------------------------------------------------------------------
bool LibraryCallKit::inline_unsafe_access(bool is_native_ptr, bool is_store, BasicType type, bool is_volatile) {
// ....
if (is_volatile) {
if (!is_store)
insert_mem_bar(Op_MemBarAcquire);
else
insert_mem_bar(Op_MemBarVolatile); // ①
}
if (need_mem_bar) insert_mem_bar(Op_MemBarCPUOrder);
return true;
}
注意 ① 处多出的一个 Volatile 屏障,可以在
x86_64.ad
文件中确认它是一个 StoreLoad 屏障。而 putOrderedXXX 则没有这个屏障。
CAS
Unsafe 中主要提供了如下方法:
// native 方法实现,有 Int、Long 变种
public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object x);
// 在 compareAndSwapObject 基础上的封装,不断执行 CAS 直到成功
public final Object getAndSetObject(Object o, long offset, Object newValue) {
Object v;
do {
v = getObjectVolatile(o, offset);
} while (!compareAndSwapObject(o, offset, v, newValue));
return v;
}
CAS 语义
Compare And Swap(CAS) 是 lock-free 算法中最基础的模块,通常由 CPU 指令直接支持。函数通常有两个参数:oldValue 与 newValue,内部逻辑的伪代码如下:
currentValue = readValue();
if (currentValue == oldValue) {
setValue(newValue);
return true;
} else {
return false;
}
CAS 机制要能正确工作,需要保证原子性和可见性。原子性的要求显而易见,在 CAS 过程中不能执行其它指令改变现有的值。同时至少要保证 readValue 读取的是最新的值,但 setValue 的值是否对其它线程可见,似乎没有保证,不过一方面一般会对
volatile 变量执行 CAS 操作,另一方面 x86 架构下使用 LOCK CMPXCHG 指令时会保证写入结果对其它线程可见。
CAS 实现
compareAndSwapObject 方法的实现可以在
unsafe.cpp
找到,一路追踪最终发现会调用
atomic.hpp:cmpxchg
。
// Performs atomic compare of *dest and compare_value, and exchanges *dest with exchange_value
// if the comparison succeeded. Returns prior value of *dest. Guarantees a two-way memory
// barrier across the cmpxchg. I.e., it's really a 'fence_cmpxchg_acquire'.
static jbyte cmpxchg (jbyte exchange_value, volatile jbyte* dest, jbyte compare_value);
inline static jint cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value);
// See comment above about using jlong atomics on 32-bit platforms
inline static jlong cmpxchg (jlong exchange_value, volatile jlong* dest, jlong compare_value);
static unsigned int cmpxchg(unsigned int exchange_value,
volatile unsigned int* dest,
unsigned int compare_value);
inline static intptr_t cmpxchg_ptr(intptr_t exchange_value, volatile intptr_t* dest, intptr_t compare_value);
inline static void* cmpxchg_ptr(void* exchange_value, volatile void* dest, void* compare_value);
这里的注释很重要,说明了至少会保证在 CAS 前加上 fence,在后面加上acquire屏障。这些内联方法在不同平台上有不同的实现,如 Linux(x86) 的实现在文件
atomic_linux_x86.inline.hpp
中:
inline jlong Atomic::cmpxchg (jlong exchange_value, volatile jlong* dest, jlong compare_value) {
bool mp = os::is_MP();
__asm__ __volatile__ (LOCK_IF_MP(%4) "cmpxchgq %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
不同的数据类型有不同的实现,这里列出的是 long 型数据的实现,可以看到用的是
cmpxchgq 指令,且在多核条件下会加 LOCK 前缀。cmpxchg 系列指令就是 x86 提供的 CAS 指令。不过我们看到代码里并没有手工加内存屏障,这是因为在 x86 架构中,
LOCK 前缀本身会实现类似 StoreLoad 屏障的功能,因此不需要额外插入屏障。
park/unpark
处理并发不可避免要处理线程的阻塞与唤醒,在 Unsafe 包中提供了下面两个函数:
public native void unpark(Object thread);
public native void park(boolean isAbsolute, long time);
这两个方法的语义在它们的注释中有比较详细的说明,这里简要翻译如下:
park 方法会阻塞当前线程,方法会在下列情况下返回(线程被唤醒):
- 有线程调用了
unpark方法,或在park前已经有线程调用了unpark方法 - 线程被中断了(
Thread::interrupt) isAbsolute为false,time > 0且已经过去了time纳秒isAbsolute为true,且自 epoch 以来已经过了time秒- 其它未知原因出错,直接返回
与 park 对应,unpark 方法用来唤醒 park。要注意 unpark 唤醒的机制是设置一个标志位:
- 调用
park时检测到标志位会清除标志并直接返回已经阻塞在park的线程在 unpark调用时会被唤醒,同样消除标志并返回
因此,unpark 调用的时机并不重要,它能保证至少“唤醒”一次 unpark。
实现
首先我们
Parker
中使用了 _counter 作为标识,它虽然是个 int,实际上只会取值 0 和 1。
class Parker : public os::PlatformParker {
private:
volatile int _counter ;
Parker * FreeNext ;
JavaThread * AssociatedWith ; // Current association
// ...
}
然后注意 park 如果需要阻塞,是通过(Linux)系统的
pthread_cond_wait
方法,等待条件变量进入阻塞:
assert(_cur_index == -1, "invariant");
if (time == 0) {
_cur_index = REL_INDEX; // arbitrary choice when not timed
status = pthread_cond_wait (&_cond[_cur_index], _mutex) ; // 阻塞
} else {
_cur_index = isAbsolute ? ABS_INDEX : REL_INDEX;
status = os::Linux::safe_cond_timedwait (&_cond[_cur_index], _mutex, &absTime) ;
if (status != 0 && WorkAroundNPTLTimedWaitHang) {
pthread_cond_destroy (&_cond[_cur_index]) ;
pthread_cond_init (&_cond[_cur_index], isAbsolute ? NULL : os::Linux::condAttr());
}
}
// ...
_counter = 0 ; // 清除标志
同时在被唤醒后继续执行,将 _counter 设置为 0。同理,unpark 方法通过
pthread_cond_signal
方法唤醒等待条件变量的线程,当然,在唤醒前会将 _counter 置为 1:
void Parker::unpark() {
int s, status ;
status = pthread_mutex_lock(_mutex);
assert (status == 0, "invariant") ;
s = _counter;
_counter = 1; // 设置标志
if (s < 1) {
// thread might be parked
if (_cur_index != -1) {
// thread is definitely parked
if (WorkAroundNPTLTimedWaitHang) {
status = pthread_cond_signal (&_cond[_cur_index]); // 唤醒线程
assert (status == 0, "invariant");
status = pthread_mutex_unlock(_mutex);
assert (status == 0, "invariant");
}
// ...
}
顺带一提,我们看到 Thead::interrupt 最终调用的 native 方法
os::interrupt
最终也会调用 Parker::unpark 来唤醒线程。
小结
本章大致从源码层面讲解了 Unsafe 提供的部分能力,这些能力是 JUC 并发类的基石,这些 unsafe 方法都是 native 方法,用来绕开 java 封装的语义,提供更底层的操作能力,而增加这么多复杂性的目的,就是提高程序的性能。
我们先简单介绍了 Java 对象的内存布局,以及获取字段偏移量的方法,偏移量是其它方法的先决条件。
之后介绍了 getXXX/putXXX 和 getXXXVolatile/putXXXVolatile,它们分别代表了 Java 中普通变量和 volatile 变量的读写能力,不同的是它们可以绕开修饰符的限制。另外还单独讲解了 putOrderedXXX,它能高效的实现延迟设置的功能。
之后介绍了 CAS,它是 lock-free 算法的基石,在 JUC 的实现中无孔不入,CAS 底层直接对应了 CPU 的指令,并保证 fence_cmpxchg_acquire 的语义,可以简单理解成保证了原子性、有序性、可见性。
最后介绍了 park/unpark 语义,用来阻塞和唤醒线程。唤醒的机制是设置与清除“标志”,因此可以多次,甚至提前唤醒。阻塞与唤醒使用了操作系统的条件变量(condition
variable)。
如果不关心底层细节只需要了解相关的语义即可,如果关心实现细节,需要理解很多内存屏障以及背后的重排序、可见性相关的内容,感兴趣的读者可以阅读相关资料,一定会有更大的收获。
参考
- The JSR-133 Cookbook for Compiler Writers 详细解释了 Java 中的内存屏障
- Java魔法类:Unsafe应用解析 分析了
Unsafe包含的方方面面和使用示例 - JUC中Atomic class之lazySet的一点疑惑 源码角度分析了 lazySet 及 putOrderedXXX 的实现原理
- JAX London 2012: Locks? We Don't Need No Stinkin'
Locks! distruptor 对一些高级特性的使用,其中包括
lazySet的讲解
Atomic
JDK 1.8 的
java.util.concurrent.atomic
包下,定义了 17 个 Atomic(原子类),它们扩展了 volatile 的语义,保证了单个变量的原子性、有序性与可见性。相比于 synchronized,原子类底层使用 CAS 实现了
lock-free 的算法,性能更高。
原子类的实现基本是基于 Unsafe 包里的更底层的能力,我们会以 AtomicInteger
为例,分析原子类的实现,同时分析其它原子类实现中的一些亮点。我们假设你已经了解了 Unsafe 类中各方法的语义,不了解的也可以看本书前面的
Unsafe 一章。
AtomicInteger
AtomicInteger、AtomicLong、及 AtomicReference 的实现类似,这里以
AtomicInteger 为例。
成员变量
AtomicInteger 类的整体结构如下:
public class AtomicInteger extends Number implements java.io.Serializable {
private static final long serialVersionUID = 6214790243416807050L;
// setup to use Unsafe.compareAndSwapInt for updates
private static final Unsafe unsafe = Unsafe.getUnsafe(); // ①
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value")); // ②
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value; // ③
//...
}
要点说明如下:
- ① 处调用
Unsafe.getUnsafe获取Unsafe实例,该方法在 JUC 中将多次出现 - ② 处获取了 ③ 中定义的
value字段对应的偏移量,后续调用Unsafe方法时使用 - ③ 中定义了保存数据的
value字段,注意它声明的是volatile
我们知道 Unsafe::compareAndSwapInt 方法是保证了有序性与可见性的,那么
value 为什么还要声明成 volatile?这里因为除了 CAS 相关的方法,
AtomicInteger 还提供了诸如 get/set 方法,这些方法需要变量是 volatile 才能保证有序性与可见性。
getAndSet
getAndSet 用于获取旧的值,并设置成新的值,要注意这个方法在执行时会“自旋”,即轮询直到设置成功。源码如下:
public final int getAndSet(int newValue) {
return unsafe.getAndSetInt(this, valueOffset, newValue);
}
其中 unsafe.getAndSetInt 的实现如下:
public final int getAndSetInt(Object o, long offset, int newValue) {
int v;
do {
v = getIntVolatile(o, offset);
} while (!compareAndSwapInt(o, offset, v, newValue));
return v;
}
这里用 getIntVolatile 保证读取的是最新的值,之后用 compareAndSwapInt 来替换成新的值。这里的自旋+获取旧值+设置新值,也是 CAS 的最典型的使用方式。
compareAndSet
compareAndSet 只是简单封装了 unsafe.compareAndSwapInt,如果当前值等于expect,将值设置为新值 update。
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
lazySet
这个方法是 unsafe.putOrderedInt 的封装,在 Unsafe 一章中说过,它保证有序性,但不保证可见性(修改立即对其它线程可见),因此性能更高。
public final void lazySet(int newValue) {
unsafe.putOrderedInt(this, valueOffset, newValue);
}
weakCompareAndSet
这是一个预留的方法,对它的预期是可能因为示知原因而失败,且不保证有序性。不过看到当前的实现与 compareAndSet 一模一样。
/**
* <p><a href="package-summary.html#weakCompareAndSet">May fail
* spuriously and does not provide ordering guarantees</a>, so is
* only rarely an appropriate alternative to {@code compareAndSet}.
*/
public final boolean weakCompareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
VMSupportsCS8
AtomicLong 中还有一个特殊的变量和方法,用来判断当前 JVM 是否支持 8 字节(long
型)的 CAS 操作,这个方法在 Updater 中会用到。
private static native boolean VMSupportsCS8();
static final boolean VM_SUPPORTS_LONG_CAS = VMSupportsCS8();
AtomicIntegerArray
这个类是对数组类型 int[] 的包装,提供的能力是对数据中某个元素的原子更新能力,它的方法是基于某个元素的偏移量完成的,我们只看看元素的定位的部分:
public class AtomicIntegerArray implements java.io.Serializable {
// ...
private static final int base = unsafe.arrayBaseOffset(int[].class);
private static final int shift;
private final int[] array;
static {
int scale = unsafe.arrayIndexScale(int[].class);
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
shift = 31 - Integer.numberOfLeadingZeros(scale);
}
private static long byteOffset(int i) {
return ((long) i << shift) + base;
}
// ...
我们看到数组的定位 byteOffset 等于 base + scale * N,我们通过
jol 库打印
System.out.println(ClassLayout.parseClass(int[].class).toPrintable());
Unsafe unsafe = getUnsafe();
System.out.println(unsafe.arrayBaseOffset(int[].class));
System.out.println(unsafe.arrayIndexScale(int[].class));
得到结果:
[I object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 16 (object header) N/A
16 0 int [I.<elements> N/A
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
16 // base = 16
4 // scale = 4
base 代表数组中第一个元素的偏移量,这里 16 代表了对象头信息,scale 代表每个元素的大小,一个 int 默认是 4 个字节。
代码中的 scale & (scale - 1) 是很趣的 Hack,用来判断一个数是否为 2 的次方。
另一个细节是代码中将 scale 转换成了 shift,并用 i << shift 计算偏移量,一般来说位移操作会比乘法快。
Striped64
Striped64 是一个内部类,用于实现 Adder 和 Accumulator。LongAdder 在高并发下性能要优于 AtomicLong,原因是 Striped64 使用了分段的技术,减少了高并发下的竞争。
Striped64 对外的语义是一个数字,在内部将数字的“值”拆成了好几部分:一个base变量和一个 cells 数组,当线程尝试修改数字(增减)时,会先尝试对 base 进行修改,如果成功则退出,如果失败则说明当前存在竞争,会根据线程的哈希值,对
cells 中的某个元素进行修改。外部需要获取数值时,需要累加 base 和 cells
中的所有元素。
相比于 Atomic 变量中所有线程竞争同一个变量,Striped64 通过将线程分散,让多个线程分别竞争数组中的某个元素,从而降低了竞争,减少了自旋的时间,最终提高了性能。分段是十分重要的减少竞争的手段,在 ForkJoinPool 中也有体现。
成员变量
Striped64 有如下成员变量:
abstract class Striped64 extends Number {
/** Number of CPUS, to place bound on table size */
static final int NCPU = Runtime.getRuntime().availableProcessors();
/** Table of cells. When non-null, size is a power of 2. */
transient volatile Cell[] cells;
/**
* Base value, used mainly when there is no contention, but also as
* a fallback during table initialization races. Updated via CAS.
*/
transient volatile long base;
/** Spinlock (locked via CAS) used when resizing and/or creating Cells. */
transient volatile int cellsBusy;
// ...
}
说明如下:
NCPU记录了系统 CPU 的核数,因为真正的并发数最多只能是 CPU 核数,因此cells数组一般要大于这个数。cells数组,大小是 2 的次方,这样将线程映射到cells元素时方便计算。base,基本数值,一般在无竞争能用上,同时在cells初始化时也会用到。cellsBusy,自旋锁,在创建或扩充cells时使用
从需求出发 Cell 类需要类似 AtomicLong,能通过 CAS 更新。实际定义如下:
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}
熟悉了 AtomicLong 会发现,Cell 的设计几乎一模一样:volatile 变量、Unsafe
加上字段的偏移量,再用 CAS 提供修改能力。
这里比较特殊的是 @sun.misc.Contended 注解,它是 Java 8 中新增的注解,用来避免缓存的伪共享,减少
CPU 缓存级别的竞争。有兴趣的可以搜索相关资料。
longAccumulate
Striped64 主要提供了 longAccumulate 和 doubleAccumulate,方法比较长,我们先从 long 的这版看起。
计算哈希
在 Striped64 中,哈希值的作用是用来分发线程到某个 cells 元素,Striped64中利用了 Thread 类中用来做伪随机数的 threadLocalRandomProbe:
public class Thread implements Runnable {
/** Probe hash value; nonzero if threadLocalRandomSeed initialized */
@sun.misc.Contended("tlr")
int threadLocalRandomProbe;
}
在 Striped64 中复制了 ThreadLocalRandom 的一些方法,用 Unsafe 来获取和修改字段值。
/**
* Returns the probe value for the current thread.
* Duplicated from ThreadLocalRandom because of packaging restrictions.
*/
static final int getProbe() {
return UNSAFE.getInt(Thread.currentThread(), PROBE);
}
/**
* Pseudo-randomly advances and records the given probe value for the
* given thread.
* Duplicated from ThreadLocalRandom because of packaging restrictions.
*/
static final int advanceProbe(int probe) {
probe ^= probe << 13; // xorshift
probe ^= probe >>> 17;
probe ^= probe << 5;
UNSAFE.putInt(Thread.currentThread(), PROBE, probe);
return probe;
}
可以理解为 getProbe 用来获取哈希值,advanceProbe 用来更新哈希值。
加锁
因为 Cells 类占用比较多的空间,所以它的初始化按需进行的,开始时为空,需要时先创建两个元素,不够用时再扩展成两倍大小。在修改 cells 数组(如扩展)时需要加锁,加锁方式如下:
(cellsBusy == 0 && casCellsBusy())
final boolean casCellsBusy() {
return UNSAFE.compareAndSwapInt(this, CELLSBUSY, 0, 1);
}
既然有 CAS 来将 cellsBusy 设成 1,那么 cellsBusy == 0 这个判断还有意义吗?从逻辑上没有区别,猜测应该是为了提高性能,变量的读取比 CAS 的代价小,因此如果 cellsBusy 已经是 1 则 CAS 大概率 失败,提前判断能提高性能。
而释放锁则直接将 cellsBusy 设置为 0 即可:
cellsBusy = 0;
另外为了保证逻辑正确,需要使用类似 Double Checked Locking 的技术,代码里多次用到了如下模式:
if (condition_met) { // 只在必要时进入
lock(); // 加锁
done = false; // 因为外层有轮询,需要记录任务是否需要继续
try {
if (condition_met) { // 前面的 if 到加锁间状态可能变化,需要重新判断
// ...
done = true; // 任务完成
}
} finally {
unlock(); // 确保锁释放
}
if (done) // 任务完成,可以退出轮询
break;
}
Accumulate 完整代码
完整代码比较长,注释如下:
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
// 获取线程的哈希值
int h;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) { // cells 已经初始化了
if ((a = as[(n - 1) & h]) == null) { // 对应的 cell 不存在,需要新建
if (cellsBusy == 0) { // 只有在 cells 没上锁时才尝试新建
Cell r = new Cell(x);
if (cellsBusy == 0 && casCellsBusy()) { // 上锁
boolean created = false;
try { // 上锁后判断 cells 对应元素是否被占用
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created) // cell 创建完毕,可以退出
break;
continue; // 加锁后发现 cell 元素已经不再为空,轮询重试
}
}
collide = false;
}
// 下面这些 else 在尝试检测当前竞争度大不大,如果大则尝试扩容,如
// 果扩容已经没用了,则尝试 rehash 来分散并发到不同的 cell 中
else if (!wasUncontended) // 已知 CAS 失败,说明并发度大
wasUncontended = true; // rehash 后重试
else if (a.cas(v = a.value, ((fn == null) ? v + x : // 尝试 CAS 将值更新到 cell 中
fn.applyAsLong(v, x))))
break;
else if (n >= NCPU || cells != as) // cells 数组已经够大,rehash
collide = false; // At max size or stale
else if (!collide) // 到此说明其它竞争已经很大,rehash
collide = true;
else if (cellsBusy == 0 && casCellsBusy()) { // rehash 都没用,尝试扩容
try {
if (cells == as) { // 加锁过程中可能有其它线程在扩容,需要排除该情形
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h); // rehash
}
else if (cellsBusy == 0 && cells == as && casCellsBusy()) { // cells 未初始化
boolean init = false;
try { // Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // 其它线程在初始化 cells 或在扩容,尝试更新 base
}
}
还有一个小细节,我们发现在判断 cells 是否为 null 及长度大于 0 时,先将 cells
赋值给临时变量,这是因为两个判断不是原子的,中间可能 cells 的值发生了变化,如再次变成了 null。
if ((as = cells) != null && (n = as.length) > 0) {
doubleAccumulate
doubleAccumulate 的整体逻辑与 longAccumulate 几乎一样,区别在于将 double
存储成 long 时需要转换。例如在创建 cell 时:
Cell r = new Cell(Double.doubleToRawLongBits(x));
doubleToRawLongBits 是一个 native 方法,将 double 转成 long。在累加时需要再转来回:
else if (a.cas(v = a.value,
((fn == null) ?
Double.doubleToRawLongBits
(Double.longBitsToDouble(v) + x) : // 转回 double 做累加
Double.doubleToRawLongBits
(fn.applyAsDouble
(Double.longBitsToDouble(v), x)))))
Adder
LongAdder 使用一个变量和一个动态增长的数组来共同保存一个 long 型的 sum 值,初始值为 0。它继承了 Striped64,在高并发时将线程分发到数组的不同元素做更新,以此来降低总体的竞争。因此相比于 AtomicLong,在高并发下 LongAdder 会更高的吞吐。不过由于将一个数值分散到多个地方,从 LongAdder 获取的值可能没法“立即”可见(累加时可能被其它线程修改了)。
LongAdder 的主体逻辑重用了 Striped64 的 accumulate 方法,需要先了解下Striped64的实现,这里只看看上层封装的内容。
add
增加某个值时,会尝试先用 casBase 来更新 base 的值;否则会尝试用 getProbe
获取线程的哈希值,找到对应的数组元素(as[getProbe() & m]),并尝试更新元素的值;如果都失败再调用 Striped64 的 longAccumulate 方法更新值。
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
代码逻辑没有特殊的地方,只是在 if 条件判断中会调用 CAS 操作来做修改,方法有副作用。这种方式在日常的编码中不提倡。
sum
sum 方法很直接,累加 base 与 cells:
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
这里的重点是 sum 方法不是原子的,在 sum 过程中,如果有其它线程在修改值,则
sum 的结果可能是“老”的。
DoubleAdder
DoubleAdder 和 LongAdder 几乎一样,只是存储是用 long 型,所以在存储/读取
double 时需要使用 Double.doubleToRawLongBits 和 Double.longBitsToDouble
做转换。
FieldUpdater
FieldUpdater 可以对其它类的 volatile 变量的包装,实现 CAS 的相关操作,相比于直接使用 AtomicInteger,它的主要优势是能节省内存。
使用示例
class MyStruct {
public volatile int intField;
}
public static void main(String[] args) {}
AtomicIntegerFieldUpdater<MyStruct> updater =
AtomicIntegerFieldUpdater.newUpdater(MyStruct.class, "intField"); // ①
MyStruct struct = new MyStruct();
updater.compareAndSet(struct, 0, 1); // ②
System.out.println(struct.intField); // 输出 1
}
上例中,我们在 ① 处创建了 FieldUpdater,可以看到创建时需要指定类和字段名。在 ②
中我们通过调用 updater 的 CAS 方法得到了 CAS 的能力。
注意的是,updater 是基于类创建的,一个 updater 可以用在类的多个实例上。这也是 FieldUpdater 的一个重要使用场景,用来节省内存。例如上例中,如果将
MyStruct 中的 volatile int 用 AtomicInteger 代替,同时又需要创建许多的实例,此时用 volatile int 加 FieldUpdater 的方式能节约不少内存(一个实例约省
16B1)。
此外要注意 FieldUpdater 的的访问是通过反射完成的,实现中限制了对字段的访问权限,尽力保持与原生 Java 字段修饰符一致。如上例中如果将 intField 改成 private
,则运行时 comapreAndSet 方法会报错。也因此,updater 更常用来访问当前类或父类的字段。
最后,FieldUpdater 对原子性的保证更弱,它只能保证 updater 的compareAndSet、set 等方法的调用间能保证原子性,如果同时还有线程直接读写类中的字段,则保证不了原子性。
FieldUpdater 类成员
在 AtomicIntegerFieldUpdater 中找到它的唯一实现类:
private static final class AtomicIntegerFieldUpdaterImpl<T>
extends AtomicIntegerFieldUpdater<T> {
private static final sun.misc.Unsafe U = sun.misc.Unsafe.getUnsafe();
private final long offset;
/**
* if field is protected, the subclass constructing updater, else
* the same as tclass
*/
private final Class<?> cclass;
/** class holding the field */
private final Class<T> tclass;
其中的 offset 是常规的字段在内存中的偏移量;cclass 用来做访问控制;
tclass 是要更新的目标类。
compareAndSet
CAS 的实现很简单,直接调用了 Unsafe 的相关方法,唯一不同是在调用前要做访问权限的检查。
public final boolean compareAndSet(T obj, int expect, int update) {
accessCheck(obj);
return U.compareAndSwapInt(obj, offset, expect, update);
}
accessCheck
访问控制不是我们讲解的重点,但也有一些看点,先看 accessCheck 的实现:
private final void accessCheck(T obj) {
if (!cclass.isInstance(obj))
throwAccessCheckException(obj);
}
只是单纯判断 obj 是不是类 cclass 的一个实例,那么 cclass 是什么?在构造函数中做了赋值:
AtomicIntegerFieldUpdaterImpl(final Class<T> tclass,
final String fieldName,
final Class<?> caller) {
// ...
// Access to protected field members is restricted to receivers only
// of the accessing class, or one of its subclasses, and the
// accessing class must in turn be a subclass (or package sibling)
// of the protected member's defining class.
// If the updater refers to a protected field of a declaring class
// outside the current package, the receiver argument will be
// narrowed to the type of the accessing class.
this.cclass = (Modifier.isProtected(modifiers) &&
tclass.isAssignableFrom(caller) &&
!isSamePackage(tclass, caller))
? caller : tclass;
// ...
}
FieldUpdater 从语义上要保持跟 Java 的权限控制一致,在 Java 中,一个
protected 字段可以被三种情况访问:类本身、子类、同 package 的其它类。换言之,一个 updater 可以访问父类、类本身、子类、及同 package 其它类的 protected
字段。但是还有一个特例:
.
├── packageA
│ ├── Super.java
│ └── SubclassA.java
└── packageB
└── SubclassB.java
在 SubclassB 中构造 Super 的 updater 时,会判断 SubclassB 能否访问
Super 中的字段,显然是可以的,因为 SubclassB 是 Super 的子类。但是在运行时,如果尝试访问 Super 任意子类的实例,如 SubclassB 的实例:
Super object = new SubclassA();
updater.compareAndSet(object, expect, update);
从技术上来说是可行的,但从语义上变成了 SubclassB 能访问 SubclassA 的
protected 变量,不符合预期。因此在构造函数的代码就是判断,当 SubclassB 与
Super 不在同一个 package 时,要求 updater 最终只能访问 SubclassB 的子类,而不是 Super 的任意子类。
AtomicLongUpdater
对于 long 型变量,系统不一定能直接支持 CAS 操作,于是它有两种实现,一种是基于 CAS 的,另一种是基于 synchronized 的。
@CallerSensitive
public static <U> AtomicLongFieldUpdater<U> newUpdater(Class<U> tclass,
String fieldName) {
Class<?> caller = Reflection.getCallerClass();
if (AtomicLong.VM_SUPPORTS_LONG_CAS)
return new CASUpdater<U>(tclass, fieldName, caller);
else
return new LockedUpdater<U>(tclass, fieldName, caller);
}
AtomicReferenceUpdater
对于更新 reference 来说,它的值类型是不确定的,因此在创建 updater 时需要额外指定值的类型:
@CallerSensitive
public static <U,W> AtomicReferenceFieldUpdater<U,W> newUpdater(
Class<U> tclass, Class<W> vclass, String fieldName) { // 注意这里的 vclass
return new AtomicReferenceFieldUpdaterImpl<U,W>
(tclass, vclass, fieldName, Reflection.getCallerClass());
}
在执行 CAS 前会判传递的值是否能转换成 vclass:
public final boolean compareAndSet(T obj, V expect, V update) {
accessCheck(obj);
valueCheck(update);
return U.compareAndSwapObject(obj, offset, expect, update);
}
private final void valueCheck(V v) {
if (v != null && !(vclass.isInstance(v)))
throwCCE();
}
static void throwCCE() {
throw new ClassCastException();
}
AtomicStampedReference
AtomicStampedReference 本身不难理解,稍微难理解的是它要解决的 ABA 问题。
ABA 问题
ABA 问题的核心是:CAS 操作在 compare 阶段,只会比较目标的部分信息,例如只比较内存地址是否相等而非对象的所有字段相等,于是 CAS 时,无法确定目标是最初看到的那个,还是被其它替换过的。
在非 GC 的语言中(如 C/C++)中实现 lock-free 算法时容易遇到这个问题,因为内存被释放时可能还有变量存放该内存的引用,而新的对象可能重用了该内存地址,造成地址相同内容不同的情形1。
考虑用链表实现一个栈:

上图的问题在于内存地址 A 被重复利用,分配给新的对象了。在线程 1 发出 CAS 指令但还未执行的过程中,线程 2 做了两次 pop,一次 push,最终将 head 的值设置成了A(4),于是线程 1 的 CAS 判断内存地址还是 A,指令执行成功,却把线程 2 push
的元素给 pop 了。
要注意的是这个行为是不是 "bug" 取决于业务的需求,如果业务上单纯是想 pop,那么逻辑正确,如果业务上线程 1 是想 pop A(1),显然就是错的。在实现 lock-free 算法时通常这个行为是错的。
另外注意 ABA 问题并不是“原子性”引起的。CAS 的 compare-and-swap 操作依旧是原子的,只是 compare 的结果不符合上层业务的预期。
解决 ABA 问题的想法也很简单,在 compare 阶段使用更全面的信息做判断,能区分两个
A 即可。常见的手段是增加一个额外的字段,记录修改的版本号,也是
AtomicStampedReference 的实现方式。
AtomicStampedReference 成员变量
代码如下:可以看到定义了 Pair 类将原本的 reference 和新增的 stamp 包装起来。后面会看到在 CAS 时会用 Pair 作为整体用于判断。
public class AtomicStampedReference<V> {
private static class Pair<T> {
final T reference;
final int stamp;
private Pair(T reference, int stamp) {
this.reference = reference;
this.stamp = stamp;
}
static <T> Pair<T> of(T reference, int stamp) {
return new Pair<T>(reference, stamp);
}
}
private volatile Pair<V> pair;
// ...
}
另一个类 AtomicMarkableReference 实现几乎相同,只是相比于使用 int 型的stamp,它使用了 boolean 型的 mark。
CompareAndSet
可以看到 CAS 需要同时判断更新 reference 和 stamp 两个元素:
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair<V> current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}
只有当 expectedReference == current.reference && expectedStamp == current.stamp 成立时,我们才认为旧值相同,需要执行 CAS。在执行 CAS 前会先判断新值是否相同,如果相同已经符合预期,没必要执行 CAS。
在执行 CAS 时,受限于 CAS 操作的粒度,并无法同时判断两个变量,依旧只能判断指针是否相同。但此时判断的是 pair 的指针,而 CAS 前通过其它手段确认 pair 的旧值与用户的预期(入参)相同。
当然,这个方法是“君子协议”,如果大家每次 CAS 都将版本号加一,自然没问题,但如果有线程刻意去回退版本号,则该方法也无法处理。
亮点:包装类实现原子性
我们知道多个变量的原子操作组合后就不再是原子的(TOCTOU 问题)。但是用包装类将多个两个变量组装,提供组装类的原子操作(相当于一个变量),则可以实现整体的原子性。
例如下面的代码,业务上希望 lower <= upper,虽然 lower 与 upper 的获取与赋值都是原子的,但整体的约束可能被打破。
public class NumberRangeService {
private AtomicInteger lower;
private AtomicInteger upper;
public int getLower() { return lower.get(); }
public int getUpper() { return upper.get(); }
public void setLower(int lower) { this.lower.set(lower); }
public void setUpper(int upper) { this.upper.set(upper); }
}
可以使用包装类,将约束包装起来,用以实现线程安全,例如:
public class NumberRange {
private int lower;
private int upper;
public NumberRange(int lower, int upper) {
if (lower > upper) { throw new IllegalArgumentException("lower should be <= upper"); }
this.lower = lower;
this.upper = upper;
}
public int getLower() { return this.lower; }
public int getUpper() { return this.upper; }
}
public class NumberRangeService {
private AtomicReference<NumberRange> range = new AtomicReference<>(new NumberRange(0, 0));
public NumberRange getRange() {
NumberRange range = this.range.get();
return new NumberRange(range.lower, range.upper);
}
public void setRange(NumberRange range) {
this.range.set(range);
}
}
在 Java 中不会发生内存地址重用的问题,因为如果存在对象的引用,则对象的内存不会被释放,也不可能被重复利用。
AbstractQueuedSynchronizer
AbstractQueuedSynchronizer 简称 AQS,是一个基于 FIFO 队列的同步器,用于实现阻塞锁(blocking locks)或其它的同步器(如 Semaphore)。JUC 中的许多锁实现(如ReentrantLock、ReentrantReadWriteLock)都依赖 AQS 来实现公平锁或不公平锁。
阻塞锁的基本要求
什么是阻塞锁?阻塞指的是抢不到锁的线程进入休眠,直到锁被释放时被唤醒。备选的方案是自旋(spin),轮询锁的状态并不断尝试抢锁,抢到为止。通常自旋的方式也称为 "active"(主动)模式,休眠模式也称为 "passive" (被动)模式。
为什么需要阻塞锁?原因有两个:一是线程阻塞可以及时释放 CPU 资源;二是阻塞一般代表会有等待队列,对线程唤醒的顺序能有合理预期(如先进先出)。而自旋锁通常无法实现。
要如何实现阻塞锁?根据前面的说法,我们需要两样道具:
- 一个状态,用于标识锁是否被占用
- 一个队列,等待的线程在队列中排队,等待锁空闲了被唤醒
这也是 AQS 实现的基本结构:

AQS 的功能
可以说 AQS 的多数操作就是使用 CAS 处理等待队列。不过为了支持更多场景,AQS 实现了更复杂的功能,主要有两个维度:
- 锁的类型
- 互斥锁,只有一个线程可以获得锁
- 共享锁,同时有多个线程可以获得锁
- 获取模式
- 阻塞获取,不中断(不抛异常)
- 可中断的阻塞获取
- 带超时时间的获取
两个维度可以任意组合,得到 6 个 acquire 方法。此外,还有 Condition(条件变量)的支持。
互斥锁
互斥锁(exclusive lock)指的是同一时刻只有一个线程能抢到锁,与之相对的是共享锁,同一时刻有多个线程能抢到锁,如读写锁允许同时有多个读锁。
对于锁的状态,AQS 使用了 volatile int state; 这样的定义,对于互斥锁来说,其实 boolean 类型就足够了,int 型能应对多数的共享锁。
对锁状态的控制,AQS抽象成了两个方法,由实现方自由实现:分别是 tryAcquire 和
tryRelease 方法,代表了尝试获取锁和尝试释放锁。尝试获取失败时 AQS 就要考虑如何将线程加入到队列中了。
AQS 的队列用双向链表实现,抛开花里胡哨的状态管理,最原始的结构如下:
static final class Node {
volatile Node prev;
volatile Node next;
volatile Thread thread;
//...
}
在 AQS 中保留了链表的头和尾:
private transient volatile Node head;
private transient volatile Node tail;
AQS 使用的是 FIFO 队列,从 tail 入队,从 head 出队。约定上,head 节点的后继节点在锁释放时需要被唤醒,唤醒后对应的线程会尝试抢锁,但不一定能成功,在不公平的抢占下,可能有插队(刚到的还没入队)的线程抢到了锁。
调用关系
粗粒度的调用关系如下:

入队(enque)
入队的代码如下所示:
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // ①
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) { // ②
t.next = node;
return t;
}
}
}
}
代码中 ① 处是为了实现性能优化,如果从始至终都没有竞争,就不需要使用到队列,所以延迟初始化链表节点节约内存。② 处尝试将新节点加入到队尾,步骤如下图所示:

注意到如果步骤 ③ 完成之前有节点访问了 node2.next,会得到 null,对于双向链表来说是有问题的,但是 AQS 对 next 指针要求可有可无,因为它的作用只是为当前节点查找后继,如是 next == null,则会从 tail 反向查找到 node2 的后继,这在 unparkSuccessor 方法中体现:
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
// 反向查找 node 的后继
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
AQS 中一般不会直接调用 enq 方法,而是调用包装方法 addWaiter:
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// 先快速尝试入队,失败时调用 enq,入队逻辑与 enq 中几乎一样
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
出队
FIFO 队列,顾名思义是队首的元素先退出。与传统的双向链表操作不同,AQS 节点出队时并不会释放节点,而是唤醒下一个等待的节点,由被唤醒的线程来释放队首的节点。如下图:

首先需要在释放锁的时候唤醒 head 对应节点的后继节点,即上图中的 node2,代码入口在 release,其中 arg 参数透传给具体的 tryRelease 实现,AQS 不关心。
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
其中 unparkSuccessor 的实现如下,查到后继节点并唤醒对应线程:
private void unparkSuccessor(Node node) {
// waitStatus 处理,现在先忽略
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
// 通过 next 找到后继节点,如果为 null 则由 tail 反向查找
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread); // 唤醒后继节点的线程
}
上面代码只是唤醒下一个等待节点,被唤醒线程尝试抢锁并释放 head 节点的逻辑,在抢锁的方法里。
抢锁(acquireQueued)
抢锁的代码入口是 acquire,调用 tryAcquire 尝试抢锁失败后调用 addWaiter
将节点入队,再调用 acquireQueued 处理状态的变化:
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
acquireQueued 的实现如下,死循环尝试抢锁直到失败或被中断。成为 head 节点的后继时会尝试抢锁,成功则成为 head 节点并释放之前的 head 节点,失败则看情况进入休眠:
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) { // 重试直到获取锁或被中断
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) { // 当前节点为 head 后继时才尝试获取锁
// 如上节出队中所说,获得锁后需要释放当前的 head 节点
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
// 看情况休眠,可能会在锁释放或接收到中断时被唤醒
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node); // 失败时需要取消操作,此处先省略
}
}
休眠
在 acquireQueued 中休眠涉及两个方法:shouldParkAfterFailedAcquire 用于检测当尝试抢锁失败后是否应该休眠,只有当前驱节点的 waitStatus 变成了 SIGNAL 后,代表前驱节点释放后会唤醒我们,这才可以安心休眠;另一个方法
parkAndCheckInterrupt 是真正执行休眠,被唤醒后检测中断的状态。
shouldParkAfterFailedAcquire 的源码如下,其中很多状态管理在共享锁中使用
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
// pred 节点状态正确,锁释放时会唤醒 node,因此可以放心休眠
return true;
if (ws > 0) {
// pred 节点取消了,跳过它找到更前面的节点
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
// 在 waitStatus == 0 或 PROPAGATE 的情况下需要将 pred 的状态设置成
// SIGNAL,保证 pred 释放锁时能唤醒 node 状态改完后 node 需要再次尝试抢锁
// ,防止 pred 节点还没看到更新后的状态就被释放了
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
方法里包含了很多状态管理,但对于互斥锁来说,主要关心 waitStatus == 0 和
waitStatus == SIGNAL 的情况,其它情况后续介绍的功能中会使用。
parkAndCheckInterrupt 实现比较简单,进入休眠,被唤醒时调用
Thread.interrupted 检查中断状态。代码如下:
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
共享锁
共享锁与互斥锁的区别在于,共享锁在同一时间能被多个线程持有,不过 AQS 中加锁条件的判断已经抽象成 tryAcquireShared 操作了,由具体的实现类实现。AQS 只负责唤醒等待共享锁的线程。
为了标识一个节点是在哪种模式(互斥/共享)下工作,Node 类需要增加额外的标识:
static final class Node {
static final Node SHARED = new Node();
static final Node EXCLUSIVE = null;
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
volatile int waitStatus;
Node nextWaiter;
// ...
}
当 nextWaiter 等于预定义的 SHARED 时认为是在共享模式下工作,后续也被用在条件变量的等待队列中。共享锁模式下节点有多种状态,用 waitStatus 存储,跟共享锁有关的主要有:
SIGNAL,代表后继节点被阻塞了,当前节点释放后需要唤醒后继节点- 为了避免竞态条件,抢锁时应先把 prev 节点的状态改成 SIGNAL,尝试抢锁,失败时再阻塞
PROPAGATE,只在 head 节点设置,代表有共享锁释放,需要唤醒后续共享节点CANCELLED,用于取消等待,抢锁出错或线程中断时使用
调用关系
粗粒度的调用关系如下:

抢共享锁
抢共享锁的操作由 doAcquireShared 方法完成,它和互斥锁的 acquireQueued 的主要结构类似:
private void doAcquireShared(int arg) {
// 创建一个共享模式的节点并加入等待队列
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head) { // 当前节点为 head 的后继时才尝试抢锁
int r = tryAcquireShared(arg);
if (r >= 0) {
// 抢锁成功,需要释放 head 节点
// 需要看情况唤醒后续的节点,如还有其它可用共享锁
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
// 看情况休眠,可能会在锁释放或接收到中断时被唤醒
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node); // 失败时需要取消操作,此处先省略不谈
}
}
doAcquireShared 和 acquireQueued 整体逻辑结构判别不大,都是在循环里抢锁,成功则释放 head 节点,失败则进入休眠。不过有一个区别是是 doAcquireShared 使用了 tryAcquireShared 抢共享锁,返回负值代表抢锁失败,正值代表剩余多少锁。
唤醒后继节点
在行为上 doAcquireShared 与 acquireQueued 不同的一点是成功抢锁后,调用的是
setHeadAndPropagate 方法,除了释放当前的 head 节点,还会看情况唤醒后续的节点,这样才能保证多余的锁也能被等待线程抢到。
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
setHead(node);
if (propagate > 0 // ① 明确知道还有锁可用
|| h == null || h.waitStatus < 0 // ② 老 head 处于特殊状态
|| (h = head) == null || h.waitStatus < 0) { // ③ 新 head 处于特殊状态
Node s = node.next;
if (s == null || s.isShared()) // ④ 后继节点是共享模式
doReleaseShared();
}
}
doReleaseShared 方法用来释放共享锁,在锁释放时也会被调用,它会根据 head 节点的状态来唤醒后继节点。我们看看 doReleaseShared 的具体实现:
private void doReleaseShared() {
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) { // ① 正常唤醒后继节点
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0)) // 清除 SIGNAL 状态
continue; // CAS 修改状态失败,重试
unparkSuccessor(h);
}
else if (ws == 0 && // ② 设置成 PROPAGATE,确保唤醒操作能传播
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // CAS 修改状态失败,重试
}
if (h == head) // 如果 head 节点变化了,则继续循环
break;
}
}
代码 ① 处判断 head 节点处于 SIGNAL 状态,说明后继节点在等待唤醒,于是调用
unparkSuccessor 唤醒节点。② 处则是将节点设置成 PROPAGATE 状态后退出。那么
PROPAGATE 状态有什么用呢?
PROPAGATE 状态的作用
跟释放互斥锁一样,释放共享锁时需要唤醒后继的节点,不同的是同一时间可能有多个共享锁被释放,但唤醒操作只能一个一个进行。需要唤醒多少线程由
tryAcquireShared 的返回值指定,且由下一个尝试抢锁的线程在
setHeadAndPropagate 方法中通过调用 doReleaseShared 执行唤醒操作。
但是被唤醒的线程 T 调用 tryAcquireShared 方法得知需要唤醒多少个线程,与执行唤醒操作之间有延迟,如果这个过程中有其它的锁释放了,则线程 T 执行唤醒时无法知晓,就会造成逻辑错误。在早期的实现中,setHeadAndPropagate 并没有 PROPAGATE 状态,就会有这个问题。早期实现的代码如下:
private void setHeadAndPropagate(Node node, int propagate) {
setHead(node);
if (propagate > 0 && node.waitStatus != 0) {
Node s = node.next;
if (s == null || s.isShared())
unparkSuccessor(node);
}
}
对应的, releaseShared 方法中也没有 PROPAGATE 的相关判断:
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
在这种实现下,考虑队列中有 t3(head) -> t1 -> t2(tail) 三个节点,t3 与不在队列中的 t4拥有锁,t3 与 t4 先后释放锁,则在下面的时序里,t1 和 t4
都不会尝试唤醒t2:

问题时序如下1:
t3锁释放,调用releaseShared后调用unparkSuccessor将head的状态置为0t1被唤醒,调用tryAcquireShared尝试抢锁,返回0,代表无多余的锁t4释放锁,调用releaseShared,读到head.waitStatus == 0(与 #1 中 head 相同),不满足waitStatus != 0的条件,不做唤醒操作。t1抢锁成功,调用setHeadAndPropagate,此时propagate == 0,没有多余的锁,于是也不做唤醒操作
最终结果是 t4 的锁释放了,却不唤醒任何后续节点,锁释放了,却没有线程被唤醒抢锁。
因此,在 t1 的 setHeadAndPropagate 要唤醒后续节点时,不能只依赖 propagate
的值,这个值可能是旧的数据。在调用 tryAcquireShared 到释放 head 节点这断期间里释放锁的线程,需要“告知”被唤醒的线程,不管 propagate 的值是什么,都要尝试唤醒后面的线程,因为有新的锁被释放了。这也就是当前的 setHeadAndPropagate 逻辑中复杂的 if 条件的来由了。
超时
互斥锁和共享锁分别有自己的超时的方法:tryAcquireNanos 和tryAcquireSharedNanos。相比于阻塞方法,超时方法接受新的参数:超时时间,在该时间内如果没有抢到锁,则返回 false 代表失败。方法的定义如下:
public final boolean tryAcquireNanos(int arg, long nanosTimeout) {...}
public final boolean tryAcquireSharedNanos(int arg, long nanosTimeout) {...}
支持超时的方法主要有两点不同:
- 每次被唤醒时都需要判断是否已经超时
- 在休眠时也需要通过
LockSupport.parkNanos定好闹钟
这里以 doAcquireNanos 方法看看它和 acquireQueued 的异同
private boolean doAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (nanosTimeout <= 0L)
return false;
final long deadline = System.nanoTime() + nanosTimeout;
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return true;
}
nanosTimeout = deadline - System.nanoTime();
if (nanosTimeout <= 0L) // 休眠之前先看是否超时
return false;
if (shouldParkAfterFailedAcquire(p, node) &&
// 如果超时时间短,则不休眠,因为自旋效率更高
nanosTimeout > spinForTimeoutThreshold)
// 休眠时要定敲钟,在 nanosTimeout 后被唤醒
LockSupport.parkNanos(this, nanosTimeout);
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
因此我们看到,对超时的支持主要依赖了 LockSupport.parkNanos 的支持,它允许我们在休眠时指定时间,过了这个时间后线程会被唤醒。这样能保证 doAcquireNanos 在超时时间后可以被唤醒,检测锁状态并退出,而不是无限制地阻塞。
中断
前文说过,Java 处理中断的方式是先唤醒进程,再由线程自己通过
Thread.interrupted() 检查中断状态并提前退出(不熟悉的同学可以复习下线程的中断)。抢锁的方法也实现了约定的中断处理逻辑。
接口定义
AQS 中的抢锁方法有两类处理中断的方式:
- 直接返回中断状态
acquireQueueddoAcquireShared
- 检测到中断时抛
InterruptedExceptiondoAcquireInterruptiblydoAcquireSharedInterruptiblydoAcquireNanosdoAcquireSharedNanos
实现
返回中断状态和抛异常的实现几乎没有区别,如 acquireQueued 对异常的处理如下:
final boolean acquireQueued(final Node node, int arg) {
// ..
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
// ...
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
// ...
}
核心的逻辑是通过 parkAndCheckInterrupt 检查状态并记录在 interrupted变量中返回,而 doAcquireInterruptibly 类似,只是检测到中断时不是记录状态,而是直接抛异常:
private void doAcquireInterruptibly(int arg)
throws InterruptedException {
// ...
for (;;) {
// ...
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
// ...
}
其中的 parkAndCheckInterrupt 方法也只是调用了 Thread.interrupted 来检测中断状态:
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
如何取消
当抢锁失败时,会调用 cancelAcquire 来取消当前节点,如下:
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
// ...
} finally {
if (failed)
cancelAcquire(node);
}
}
取消的逻辑比较复杂,我们下节单独介绍。
取消
当某个线程在抢锁时因为中断、超时等原因出错时,就需要“取消”抢锁。直觉上,取消等待需要如下操作:
- 将当前节点从等待队列中移除,这样前驱节点就不会尝试唤醒当前节点了
- 有必要时唤醒后继节点,例如移除自己的时候前驱节点执行了唤醒操作,而后继节点错过了
代码实现
AQS 中的取消操作的大致思路类似,代码如下(原代码中的注释也很清晰,建议直接阅读):
private void cancelAcquire(Node node) {
if (node == null)
return;
// ① 如果前驱节点尝试唤醒 node,在调用 `LockSupport.unpark` 时会忽略 null
node.thread = null;
// ② 查找前驱节点,忽略 CANCELLED 节点(waitStatus > 0 的只有 CANCELLED 状态)
Node pred = node.prev;
while (pred.waitStatus > 0)
node.prev = pred = pred.prev;
// ③ 记录前驱节点的 next 指针,后续的 CAS 中使用,如果 CAS 失败了,代表同
// 时有其它修改 next 指针的操作,如其它的取消操作,则不需要做任何其它操作
Node predNext = pred.next;
// ④ 这里不需要使用 CAS,本身赋值的操作是原子的
// 赋值成功前,因为 thread == null,不会受其它线程的影响
// 赋值成功后,其它节点会忽略当前节点,如 ② 中一样
node.waitStatus = Node.CANCELLED;
// ⑤ 当前节点在等待队列的队尾,尝试从队列中移除自己
// 如果失败则说明有新入队的节点,真正的释放操作在
// shouldParkAfterFailedAcquire 方法中完成
if (node == tail && compareAndSetTail(node, pred)) {
compareAndSetNext(pred, predNext, null);
} else {
// ⑥ 如果后继节点需要被唤醒,先尝试设置前驱节点的 next 指针,当前驱执行
// 唤醒时就能唤醒后继节点。如果失败了则手工唤醒它。
int ws;
if (pred != head &&
((ws = pred.waitStatus) == Node.SIGNAL ||
(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
pred.thread != null) {
Node next = node.next;
if (next != null && next.waitStatus <= 0)
compareAndSetNext(pred, predNext, next);
} else {
unparkSuccessor(node);
}
node.next = node; // help GC
}
}
节点释放
上面的代码中,我们看到只是对节点的 next 的指针有操作,而 pred 没动过,这意味着节点还在队列中,那什么时候会被释放呢?在 shouldParkAfterFailedAcquire 方法中:
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
return true;
if (ws > 0) {
// 节点休眠前要保证将前驱节点的状态改为 SIGNAL
// 当前驱节点处于 CANCELLED 状态时,需要跳过节点向前寻找
// 直到非取消的节点为止(head 节点不可能处于 CANCELLED 状态)
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
正确性分析(大概)
cancelAcquire 的主要流程“显然”是正确的,不过仔细一想又不太明白为什么。这里我们大致分析一下。
AQS 中的节点能分隔信号,唤醒操作不会跨节点传递,修改前驱的状态也不会跨节点进行。例如队列 head -> t1 -> t2 -> t3 <- tail,前驱节点 t1 的操作不会作用到后继节点 t3,反之亦然。前驱节点t1 的操作只能是唤醒当前节点 t2,后继节点
t3 的操作只能是尝试修改 t2 的 next 指针以及将 t2 的状态成 SIGNAL,而无法修改 t1 的状态。
而对于将要取消的节点来说,被前置唤醒无关紧要;被后继修改 next 指针,修改状态变成 SIGNAL 也不在意,因为状态修改的主要目的是保证自己能唤醒后继,而这在
cancelAcquire 中本来就要处理。
当状态设置成 CANCELLED 之后,前驱的操作依旧不会跨越当前节点,但后续的操作可能忽略取消节点,作用到前驱节点上。但是后继节点(在shouldParkAfterFailedAcquire方法中)跨越 CANCELLED 节点的修改前驱状态,背后的目的也是让前驱能正常唤醒自己。
于是在取消节点尝试唤醒后继节点时,会首先尝试把要唤醒的后继节点托付给前驱节点,前提是它的状态符合预期(如状态是 SIGNAL )。而如果前驱节点不符合预期,就直接唤醒后续节点,后继节点会尝试抢锁,失败后会再自己找到合适的前驱节点。
help GC
在 AQS 中多次出现设置 next 指针的操作,且注释为 "help GC",它的作用到底是什么?
如果一个节点不再被引用,那么 GC 算法是可以正常回收它的,正确性没有问题。问题出在性能上。如下图,head 和 node 1 活过一轮 Full GC 被放入老年代中,之后 head 指向了其它节点。

发生 Young GC 时,JVM 会认为 Old Gen 中的对象还活着,于是 node 2 在 Young GC
时会被认为存在引用,不被回收。意味着 node 1 引用的整条链路,虽然已经没用了,却只能等 Full GC 才能回收。相反,如果及时将每个节点的 next 置为 null,则虽然node 1 在 Old Gen 里无法被 Young GC 回收,但其它还在 Young Gen 里的节点能被回收的,整体上减少了 Full GC 的次数。
已经没用却不被 GC 回收的内存也被称为 Floating Garbage。这个问题在 StackOverflow 上有描述,指向的 JDK-6805775 和 JDK-6806875 也有详细的描述,建议阅读。
条件变量
如果有线程需要在某些“条件”满足后才接着后续操作,要如何实现?例如父线程需要等待子线程结束后才继续执行(即 join 操作)。简单的做法是轮询一个变量,其它线程在条件满足时置为 true,不过轮询的方法浪费 CPU 且不好控制。
条件变量(英文 Condition、Condition queues 或 Condition variable)提供了一种机制,能让一个线程挂起(或称休眠、阻塞),直到某此条件满足为止。由于对状态的查询修改通常是并发进行的,通常需要某种形式的锁来保护状态。也因此条件变量的核心特性是在挂起线程时,会释放对应的锁;线程被唤醒返回前,一定要抢到对应的锁。
另外注意 ConditionObject 只能用在互斥锁中,如 ReentrantLock 和
ReentrantReadWriteLock 中的 WriteLock。
基本结构
条件变量本质上还是一个等待队列,AQS 中使用单向链表来实现,成员变量如下:
public class ConditionObject implements Condition, java.io.Serializable {
private static final long serialVersionUID = 1173984872572414699L;
/** First node of condition queue. */
private transient Node firstWaiter;
/** Last node of condition queue. */
private transient Node lastWaiter;
// ...
}
ConditionObject 比较特殊的是它是 AbstractQueuedSynchronizer 的一个内部类,且不是静态类,这意味着在 ConditionObject 内可以访问 AQS 的成员变量,侧面说明条件变量是和“锁”绑定的。
通过 firstWaiter 和 lastWaiter 构建的队列称为等待队列,而对应 AQS 中抢锁用的队列(用 head 和 tail 构建择业双向链表)称为同步队列。一个 Node 可以同时加入等待队列和同步队列。
等待
线程等待某个变量之前,需要先抢到相应的锁,之后调用 await 挂起线程,await需要将线程加入等待队列并释放锁,在 await 返回前需要再抢到锁。方法实现如下:
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException(); // ① 检测到中断,抛异常
Node node = addConditionWaiter(); // ② 将线程加入等待队列
int savedState = fullyRelease(node); // ③ 释放对应的锁,会返回释放前锁的状态
int interruptMode = 0;
while (!isOnSyncQueue(node)) { // ④ 被意外唤醒的话需要再次挂起
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
// 接收到 signal,返回前需要再抢到锁
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
}
addConditionWaiter 单纯地处理链表入队,由于约定 await 前已经抢到了互斥锁,此处没有竞争:
private Node addConditionWaiter() {
Node t = lastWaiter;
// If lastWaiter is cancelled, clean out.
if (t != null && t.waitStatus != Node.CONDITION) {
unlinkCancelledWaiters();
t = lastWaiter;
}
// 加入链表末尾
Node node = new Node(Thread.currentThread(), Node.CONDITION);
if (t == null)
firstWaiter = node;
else
t.nextWaiter = node;
lastWaiter = node;
return node;
}
唤醒
唤醒有两个方法:signal 和 signalAll,区别在于 signalAll 会唤醒等待队列中的所有线程。signal 方法实现如下:
public final void signal() {
if (!isHeldExclusively()) // ① 必须保证持有锁
throw new IllegalMonitorStateException();
Node first = firstWaiter;
if (first != null)
doSignal(first); // ② 唤醒队首的线程
}
而 doSignal 的实现如下,不断将队首的节点出队:
private void doSignal(Node first) {
do {
if ( (firstWaiter = first.nextWaiter) == null) // ① 将 first 移出队列
lastWaiter = null;
first.nextWaiter = null;
} while (!transferForSignal(first) && // ② 唤醒线程
(first = firstWaiter) != null);
}
唤醒操作在 transferForSignal 中实现:
final boolean transferForSignal(Node node) {
// ① 节点状态不为 CONDITION,说明已经被取消了,不进行唤醒
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
Node p = enq(node); // ② 将节点加入到同步队列,返回之前的队尾节点
int ws = p.waitStatus;
// ③ 如果设置前驱节点的状态失败(如前驱已被取消)则直接唤醒线程
// 唤醒后的线程会在 `await` 中执行 `acquireQueued` 直到抢锁成功
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
LockSupport.unpark(node.thread);
return true;
}
意外唤醒
Condition 的接口中声明,要假设 await 方法可能被意外唤醒,从 await 的视角,被唤醒后需要确认自己是否在同步队列(sync queue)中,节点在同步队列才能在
await 中尝试抢锁并返回。实现如下:
final boolean isOnSyncQueue(Node node) {
// ① 进入同步队列时,waitStatus 为 0,且 prev 指向前驱节点
// 之后节点可能被取消,状态变为 CANCELLED
if (node.waitStatus == Node.CONDITION || node.prev == null)
return false;
if (node.next != null) // ② 存在后继节点,肯定在同步队列中
return true;
// ③ 兜底,从 tail 查找,确保 node 已经被加入同步队列
return findNodeFromTail(node);
}
取消
发生中断或失败时,先把节点设置为 CANCELLED 状态,再从队列中移除。移除操作实际分了两步,先将节点加入同步队列,这样保证 await 返回时能调用acquireQueued抢锁,再在 acquireQueued 中检测中断,并在返回时调用cancelAcquire 将节点状态改为 CANCELLED。
final boolean transferAfterCancelledWait(Node node) {
if (compareAndSetWaitStatus(node, Node.CONDITION, 0)) {
enq(node);
return true;
}
// 在 CAS 中输给了 signal,最终目标都是加入同步队列,自旋等待即可
while (!isOnSyncQueue(node))
Thread.yield();
return false;
}
检测到中断时节点会被加入同步队列,而直到 signal 方法发生时节点才会被移出等待队列,此时节点会存在于两个队列中。unlinkCancelledWaiters 方法能将状态为
CANCELLED 的节点移出等待队列,它要求调用前已经抢到锁:
private void unlinkCancelledWaiters() {
Node t = firstWaiter;
Node trail = null;
while (t != null) {
Node next = t.nextWaiter;
if (t.waitStatus != Node.CONDITION) {
t.nextWaiter = null;
if (trail == null)
firstWaiter = next;
else
trail.nextWaiter = next;
if (next == null)
lastWaiter = trail;
}
else
trail = t;
t = next;
}
}
小结
AbstractQueuedSynchronizer(AQS) 本身的想法很朴素:一个共同抢占的状态加上一个等待队列。但由于涵盖了许多的功能(如超时、中断、取消等),它的代码实现显得很复杂。
个人觉得看代码过程中可以注意几个点:
- AQS 的整体结构,为什么它能成为阻塞锁实现的基本框架
- 如何用 CAS 操作实现无锁的队列(入队、出队等)
- 如何维护 Java 关于中断处理的约定
- 欣赏如何用一个 Node 结构实现抢锁和条件变量
- 学习一些实现上的细节(如 PROPAGATE 状态的作用,help GC 的原因)
还有一些深层次原理上的东西可能在文章中没有体现(例如 AQS 基于 CLH 队列,有一些缓存上的优点),如果有兴趣可以查阅相关的论文。 The java.util.concurrent Synchronizer Framework 是 AQS 作者 Doug Lee 关于 AQS 的介绍,可以作为一个起点。
Lock
ReentrantLock
ReentrantLock 中的 Reentrant 代表“可重入”,持有锁的线程在调用 lock 时依旧可以成功,这样能防止持有锁的线程调用需要抢锁的函数导致的死锁问题。
ReentrantLock 通过内部的 Sync 类来完成锁的功能,Sync 类扩展了 AQS,重用AQS 的各项同步功能。ReentrantLock 再扩展了 Sync 实现了 FairSync 和
NonFairSync 分别用于公平锁和非公平锁。
Sync
Sync 在 AQS 的基础上增加了一些辅助方法,主要讲解 nonfairTryAcquire
与 trtryRelease。
nonfairTryAcquire
实现了非公平的抢锁操作,同时处理了“可重入”的功能,代码如下:
@ReservedStackAccess // ①
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) { // 在 ReentrantLock 中,state = 0 代表锁没有被占用
if (compareAndSetState(0, acquires)) { // 尝试抢锁
// 抢锁成功,将拥有锁的线程标记为当前线程
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) { // ② 拥有锁的线程为当前线程时“可重入”
int nextc = c + acquires; // 锁被使用的次数加 acquires
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
其中 ① 中是 JEP 270 新增的一个注解,为当前方法分配新的栈空间,防止因为 StackOverflowError 导致方法提前退出,从而引发锁状态不一致的问题。
“非公平”体现在只要检测到锁可用(c == 0)则尝试抢锁,而不管当前队列中是否有其它等待锁的线程。
tryRelease
tryRelease 用于释放当前锁,由于释放锁的前提是线程已经拥有锁,因此逻辑是单线程操作,没有什么特殊的。
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread()) // ③
throw new IllegalMonitorStateException(); // 确保当前线程拥有锁
boolean free = false;
if (c == 0) {
// 由于可重入,释放锁不代表锁就可用了,还需要确保 c == 0
free = true;
setExclusiveOwnerThread(null); // ④
}
setState(c);
return free;
}
这里延伸的一个有趣的点是保存持锁线程的变量的可见性问题,
getExclusiveOwnerThread 定义如下:
public abstract class AbstractOwnableSynchronizer
implements java.io.Serializable {
private transient Thread exclusiveOwnerThread;
protected final void setExclusiveOwnerThread(Thread thread) {
exclusiveOwnerThread = thread;
}
protected final Thread getExclusiveOwnerThread() {
return exclusiveOwnerThread;
}
// ...
}
可以看到 exclusiveOwnerThread(以下简称 owner)并没有用 volatile 定义,那在 ② 和 ③ 中如何保证 getExclusiveOwnerThread 得到的就是最新的值?
事实上无法保证其它线程看到的就是最新的值,只是不影响正确性1,注意到:
- 首先同一个线程是能看到最新的变量值的,这使得同线程中 ② 能正确进入。
tryRelease中 ④ 设置为null后有setState操作,因此能保证owner = null能被其它线程中的nonfairTryAcquire与tryRelease感知- ② 中其它线程无论看到最新的
null还是旧的owner值,条件都不成立,不影响正确性 - 同样
tryRelease中的 ③ 无论看到最新的null还是旧的owner,条件都不成立,不影响正确性
非公平锁: NonfairSync
非公平锁的组件都已经就位,只需要用 nonfairTryAcquire 实现 tryAcquire 即可:
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}
公平锁: FairSync
公平体现在:新到的线程要抢锁时,需要先看看等待队列中是否有其它的线程,有则需要排队:
@ReservedStackAccess
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() && // 唯一区别:检查当前是否有其它线程在等待
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
hasQueuedPredecessors 方法在 AQS 中实现,需要检查队列是否有其它等待的节点:
public final boolean hasQueuedPredecessors() {
Node h, s;
if ((h = head) != null) {
if ((s = h.next) == null || s.waitStatus > 0) {
s = null; // next 为 null 时有可能是中间状态,从后往前遍历
for (Node p = tail; p != h && p != null; p = p.prev) {
if (p.waitStatus <= 0)
s = p;
}
}
if (s != null && s.thread != Thread.currentThread())
return true;
}
return false;
}
小结
JUC 中的锁都建立在 AQS 之上,在 AQS 之上,ReentrantLock 主要是通过
exclusiveOwnerThread 来实现可重入,通过 state 来实现独占锁,最后通过
hasQueuedPredecessors 来实现抢占公平。
我们也看到即使是简单的逻辑中也暗藏玄机:可见性,在看 JUC 代码时我们要保持警惕,很多看着理所当然的代码实际上是精心优化的结果。
ReentrantReadWriteLock
ReentrantReadWriteLock 与 ReentrantLock 一样都是可重入锁,不同的是
ReentrantReadWriteLock 其实是两个锁:读锁是共享锁,写锁是独占锁,也因此常在读的吞吐高于写时使用。与 ReentrantLock 类似,ReentrantReadWriteLock 也是先实现了自己的 Sync,再衍生出公平锁与非公平锁。
Sync
我们知道 AQS 的 state 是 int 型,ReentrantReadWriteLock 中的 Sync 用低位 16 位表示写锁,高位 16 位表示读锁,代码中定义了一些掩码用于快速计算:
abstract static class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 6317671515068378041L;
static final int SHARED_SHIFT = 16;
static final int SHARED_UNIT = (1 << SHARED_SHIFT);
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;
// 持有读锁的数量,取高位 16 位
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }
// 持有写锁的数量,取低位 16 位
static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }
// ...
}
同时由于有多个线程可获取读锁,且每个线程都是可重入的,因此需要为每个线程记录获取读锁的个数,如下:
abstract static class Sync extends AbstractQueuedSynchronizer {
// ...
// 用于记录哪个线程占了多少个读锁
static final class HoldCounter {
int count; // initially 0
// Use id, not reference, to avoid garbage retention
final long tid = LockSupport.getThreadId(Thread.currentThread());
}
static final class ThreadLocalHoldCounter
extends ThreadLocal<HoldCounter> {
public HoldCounter initialValue() {
return new HoldCounter();
}
}
// 使用 ThreadLocal 来分线程记录持有多少读锁
private transient ThreadLocalHoldCounter readHolds;
// 优化:保存上一个获取读锁的线程的 HoldCounter
private transient HoldCounter cachedHoldCounter;
// ...
}
tryAcquire
tryAcquire 用于获取写锁,源码的注释比较清晰:
@ReservedStackAccess
protected final boolean tryAcquire(int acquires) {
// 流程如下:
// 1. 如果读锁不为 0 或写锁不为零且持锁线程不是当前线程,失败
// 2. 如果计数器饱和了,失败
// 3. 否则通过 writerShouldBlock 检测公平性,看情况获取锁
Thread current = Thread.currentThread();
int c = getState();
int w = exclusiveCount(c);
if (c != 0) {
// 说明有线程持有锁(读锁还是写锁不确定)
// 注意如果 c != 0 且 w == 0,则读锁 != 0
if (w == 0 || current != getExclusiveOwnerThread())
return false;
// 计数器饱和
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// 可重入抢锁
setState(c + acquires);
return true;
}
if (writerShouldBlock() || // 公平性检测
!compareAndSetState(c, c + acquires))
return false;
setExclusiveOwnerThread(current); // 和 ReentrantLock 一样,设置持锁线程
return true;
}
tryRelease
tryRelease 用来释放写锁,与 ReentrantLock 中的释放锁操作几乎一样:
@ReservedStackAccess
protected final boolean tryRelease(int releases) {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
int nextc = getState() - releases;
boolean free = exclusiveCount(nextc) == 0;
if (free)
setExclusiveOwnerThread(null);
setState(nextc);
return free;
}
tryAcquireShared
tryAcquireShared 用于获取读锁,可以获取读锁的条件有:
- 没有线程持有锁
- 当前线程或其它线程持有读锁
- 当前线程持有写锁
@ReservedStackAccess
protected final int tryAcquireShared(int unused) {
// 流程如下:
// 1. 如果有其它线程持有写锁,失败
// 2. 否则检测公平性并尝试抢锁
// 3. 抢锁失败,使用 fullTryAcquireShared 更全面地尝试
Thread current = Thread.currentThread();
int c = getState();
if (exclusiveCount(c) != 0 && // 有线程持有写锁
getExclusiveOwnerThread() != current) // 且不是当前线程
return -1;
int r = sharedCount(c);
if (!readerShouldBlock() && // 公平性检测
r < MAX_COUNT &&
compareAndSetState(c, c + SHARED_UNIT)) { // 尝试抢锁
if (r == 0) { // 当前线程是第一个抢锁的线程,做记录
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else { // 更新线程读锁数量,过程中优先使用缓存
HoldCounter rh = cachedHoldCounter;
if (rh == null ||
rh.tid != LockSupport.getThreadId(current))
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
}
return 1;
}
// 抢锁失败,使用完整版抢锁逻辑
return fullTryAcquireShared(current);
}
fullTryAcquireShared
fullTryAcquireShared 看起来很冗长,它与 tryAcquireShared 的逻辑几乎没啥区别,只是一个自旋版本。
final int fullTryAcquireShared(Thread current) {
HoldCounter rh = null;
for (;;) {
int c = getState();
// 先检测是否有资格抢锁
if (exclusiveCount(c) != 0) {
if (getExclusiveOwnerThread() != current)
return -1;
// 否则当前线程持有写锁,有资格抢写锁
} else if (readerShouldBlock()) { // 公平性原因要求当前线程阻塞,说明当前线程需要进入队列等待
// 只有当前抢锁操作为可重入操作,才认为抢锁失败
// 换句话说,可重入优先于公平性,否则容易造成死锁
if (firstReader == current) {
// assert firstReaderHoldCount > 0;
} else {
if (rh == null) {
rh = cachedHoldCounter;
if (rh == null ||
rh.tid != LockSupport.getThreadId(current)) {
rh = readHolds.get();
if (rh.count == 0)
readHolds.remove();
}
}
if (rh.count == 0)
return -1;
}
}
if (sharedCount(c) == MAX_COUNT) // 计数器饱和
throw new Error("Maximum lock count exceeded");
if (compareAndSetState(c, c + SHARED_UNIT)) { // 抢锁成功则更新状态
if (sharedCount(c) == 0) {
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
if (rh == null)
rh = cachedHoldCounter;
if (rh == null ||
rh.tid != LockSupport.getThreadId(current))
rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
cachedHoldCounter = rh; // cache for release
}
return 1;
}
}
}
tryReleaseShared
tryReleaseShared 用于释放读锁,主要功能是修改线程的读锁计数,完成后需要自旋调用 CAS 完成对 state 的修改:
@ReservedStackAccess
protected final boolean tryReleaseShared(int unused) {
Thread current = Thread.currentThread();
if (firstReader == current) {
// assert firstReaderHoldCount > 0;
if (firstReaderHoldCount == 1)
firstReader = null;
else
firstReaderHoldCount--;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null ||
rh.tid != LockSupport.getThreadId(current))
rh = readHolds.get();
int count = rh.count;
if (count <= 1) {
readHolds.remove();
if (count <= 0) // 释放了过多的锁,属于代码逻辑错误
throw unmatchedUnlockException();
}
--rh.count;
}
for (;;) {
int c = getState();
int nextc = c - SHARED_UNIT;
if (compareAndSetState(c, nextc))
// Releasing the read lock has no effect on readers,
// but it may allow waiting writers to proceed if
// both read and write locks are now free.
return nextc == 0;
}
}
非公平锁:NonfairSync
对于非公平锁来说,写锁永远都不需要阻塞(因为不公平,不需要等待)。理论上读锁也一样,但是为了防止大最线程抢读锁,导致写锁饥饿死锁,于是使用保护机制:如果等待队列的队首在等待写锁,则当前抢读锁的线程选择退让。实现如下:
static final class NonfairSync extends Sync {
final boolean writerShouldBlock() {
return false; // writers can always barge
}
final boolean readerShouldBlock() {
return apparentlyFirstQueuedIsExclusive();
}
}
apparentlyFirstQueuedIsExclusive 实现如下:
final boolean apparentlyFirstQueuedIsExclusive() {
Node h, s;
return (h = head) != null &&
(s = h.next) != null &&
!s.isShared() &&
s.thread != null;
}
公平锁:FairSync
抢锁时需要先检查是否有其它线程等待,与 ReentrantLock 一样使用
hasQueuedPredecessors 判断:
static final class FairSync extends Sync {
final boolean writerShouldBlock() {
return hasQueuedPredecessors();
}
final boolean readerShouldBlock() {
return hasQueuedPredecessors();
}
}
小结
ReentrantReadWriteLock 是 JUC 中最复杂的锁实现,好在有 AQS 的帮助,整体的逻辑不复杂。
代码中的亮点有:
- 使用 int 的高低位分别表示读写锁,变向帮助了锁降级功能的实现
- 一些性能的优化,如
firstReader,cachedHoldCounter,低并发度时能减少很多访问次数 - 避免写锁饿死,采取的启发式的“公平”逻辑
StampedLock
ReentrantReadWriteLock 在大量读锁和少量写锁的情形下,容易造成写锁饥饿。
StampedLock 是 JDK 1.8 增加的实现,它不依赖 AQS,极大提高了读写锁的性能,但是它不支持“重入”,概念层面也比较难理解,还有一些顺序性相关的问题。因此设计上是希望在库里使用,而非业务代码中。
使用
StampedLock 有三种锁模式:
- 写锁
writeLock(),tryWriteLock()与tryWriteLock(long time, TimeUnit unit)- 这些方法都会返回一个 long 型变量,代表锁的当前版本和锁模式
- 读锁
readLock(),tryReadLock()与tryReadLock(long time, TimeUnit unit)
- 乐观读
tryOptimisticRead()与validate(long stamp)tryOptimisticRead乐观读取,已有写锁返回 0, 否则返回一个版本号validate用于检测版本号是否合法,如果上次读取后没有加过写锁则返回true- 该模式是
StampedLock与ReentrantReadWriteLock的主要区别
它还支持锁的升级和降级:tryConvertToWriteLock(long stamp)、
tryConvertToReadLock(long stamp) 和 tryConvertToOptimisticRead(long stamp)
细节
锁模式
StampedLock 使用了 long 型表示版本号(stamp)和锁状态,二者的编码模式有一定区别,对于 stamp,会计算 stamp & 0xFF,然后有如下状态:
1000_0000(WBIT)代表处于写锁模式0000_0000为 0 时代表处于乐观锁模式0111_1110(RFULL)代表持有读锁的线程数已满(126)- 其它情况也是读锁模式
而对于锁状态(state),也会先计算 state & 0xFF,再看状态:
0代表锁空闲0111_1111(RBITS) 是临时状态,代表读锁数量将要溢出