线程的代价
在 Java 中使用线程,通常不鼓励直接创建线程,而推荐使用线程池。在《Java 并发编程实战》的第 6 章中提到这几个问题:
- 线程生命周期的开销高。如线程的创建和销毁,需要操作系统辅助
- 资源消耗。大量如空闲的线程会占用内存,大量线程竞争 CPU 时会有额外开销
- 稳定性。通常操作系统限制了一些资源,如最大线程数,线程的栈大小等。过多线程会可能会出错
本章我们来具体聊一聊这些代价有多大。我们会尽量给一些量化的结论,但不要太过绝对化,生产中还要以实际的性能测试结果为准。
线程创建
在 Java 中创建一个线程分为两步:
Thread thread = new Thread(() -> ...);
thread.start();
其中 new 操作只是调用了 Thread::init 方法做了一些初始化的操作,此时还没有跟操作系统交互。Java 的线程是直接与操作系统线程是 1:1 的,在 Thread::start
时会调用操作系统的 API 创建 native thread(例如 Linux 下会调用 glibc 的
pthread_create 创建)。
我们用 JMH 框架做了一个简单的测试,测试代码如下:
@BenchmarkMode({Mode.AverageTime})
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@State(Scope.Benchmark)
@Warmup(iterations = 3)
public class MyBenchmark {
@Param({"1000", "2000", "3000"})
private int numThreadsToCreate;
@Benchmark
public void threadCreation(Blackhole bh) throws InterruptedException {
List<Thread> threads = new ArrayList<>(numThreadsToCreate);
for (int i = 0; i < numThreadsToCreate; i++) {
threads.add(new Thread(() -> bh.consume(1)));
}
bh.consume(threads);
for (Thread thread : threads) {
thread.start();
}
for (Thread thread : threads) {
thread.join();
}
}
}
最终的得到的结果:
new Thread大概是每个线程2usThread::start大概每个线程70us
换句话说,每秒可以创建约 1.4w 个线程,对于通常的使用来说,绝对是够用的。
内存消耗
Java(操作系统)会为每个线程的堆栈分配内存,线程一天不退出,内存一天就不释放(注意栈的内存属于“堆外内存”)。
Java 中可以通过 -Xss 来设置,在调用诸如 pthread_create 等方法时,JVM 会将
Xss 的值作为参数,决定了创建线程的栈空间大小,默认是 1024KB。那么理论上,你创建了 1000 个线程,就占用了约 1G 的内存,是很可怕的。
不过,操作系统有个机制叫作“虚拟内存”,如果只是申请内存,那么操作系统只分配了虚拟内存(可以理解为只做登记),只有当真正去访问这些内存时,操作系统才会将虚拟内内存映射到物理内存上,才真正消耗物理内存。
当然,如果是在 32 位机器上,虚拟内存的空间也只有 4G,如果申请的虚拟内存用完,程序也申请不到更多的内存了。但是现在几乎是 64 位的机器,不需要担心虚拟内存被分配完的情况。
因此:除非线程栈真的被使用了,否则几乎不占用物理内存。
那么如何验证上面的信息呢?首先我们可以通过下面命令,在 Java 程序结束后打印内存使用情况1:
- 启动程序时加上参数
-XX:NativeMemoryTracking=summary - 等命令启动后使用
jcmd <pid> VM.native_memory summary查看内存详情 - 也可以通过
XX:+UnlockDiagnosticVMOptions -XX:NativeMemoryTracking=summary -XX:+PrintNMTStatistics在程序结束后打印相关信息
如何,我们创建 1000 个线程,线程启动后 sleep 100s。
Java Heap (reserved=4194304KB, committed=262144KB)
(mmap: reserved=4194304KB, committed=262144KB)
Class (reserved=1066165KB, committed=14261KB)
(classes #590)
(malloc=9397KB #1569)
(mmap: reserved=1056768KB, committed=4864KB)
Thread (reserved=1048931KB, committed=1048931KB)
(thread #1021) # <- 创建了 1000+ 线程
(stack: reserved=1044480KB, committed=1044480KB) # 占用了 1020M 虚拟内存
(malloc=3256KB #5110)
(arena=1195KB #2040)
...
含义如下:
thread #1021表示创建了 1021 个线程reserved=1044480KB代表保留了内存,如启动参数-Xms100m -Xmx1000m,则 Heap 的 reserved 会对应 1000mcommitted=1048931KB代表真正分配的虚拟内存(malloc/mmap),但注意不代表真正占用的物理内存
那么如何确认实际占用的物理内存呢?在 MacOS 下可以使用 vmmap <pid>,Linux 下使用 pmap <pid> 来查看,这里以 vmmap 的输出为例:
REGION TYPE START - END [ VSIZE RSDNT DIRTY SWAP] PRT/MAX SHRMOD PURGE REGION DETAIL
...
Stack 000070000d532000-000070000d5b4000 [ 520K 36K 36K 0K] rw-/rwx SM=PRV thread 1
Stack 000070000d5b8000-000070000d6b7000 [ 1020K 108K 108K 0K] rw-/rwx SM=ZER thread 2
Stack 000070000d6b8000-000070000d7ba000 [ 1032K 8K 8K 0K] rw-/rwx SM=PRV thread 3
Stack 000070000d7bb000-000070000d8bd000 [ 1032K 8K 8K 0K] rw-/rwx SM=PRV thread 4
Stack 000070000d8be000-000070000d9c0000 [ 1032K 8K 8K 0K] rw-/rwx SM=PRV thread 5
...
Stack 000070003b540000-000070003b63f000 [ 1020K 12K 12K 0K] rw-/rwx SM=ZER thread 729
Stack 000070003b643000-000070003b742000 [ 1020K 12K 12K 0K] rw-/rwx SM=ZER thread 730
Stack 000070003b746000-000070003b845000 [ 1020K 12K 12K 0K] rw-/rwx SM=ZER thread 731
...
从 REGION TYPE 和 DETAIL 列可以得知这些是为线程分配的栈空间,其中的 VSIZE 代表虚拟内存,RSDNT 代表驻留内存(物理内存)。可以看到大概分配了 1020K 虚拟内存,但实际占用只有 12K。
同样的,除非有特殊需求,否则其实日常使用中,线程实际上占不了多少内存。
线程切换
在并发编程里,线程切换的开销也是常常提到的一个。线程切换(Context Switching),也叫上下文切换,指的是操作系统在中断线程运行时保存线程的上下文信息,之后恢复运行时再恢复上下文信息的操作。一般有这么几种情形:
- 多任务:例如线程运行时间太长被操作系统抢占,或线程调用了阻塞方法,主动暂停等。
- 处理中断信号:如我们敲了键盘,从硬盘读取的数据准备就绪等,一般发生在操作系统底层。
- 用户态与内核态的切换:当操作系统在用户态与内核态切换时(如调用
read读取数据),可能需要线程切换。
当许多线程长时间运行时,不可避免地会发生一些线程切换操作,由于 CPU 数量有限,通常线程越多,发生的切换也越多。类比的话可以理解成开车,由于道路拥堵,每辆车都走走停停,花费了更多的时间。
问题在于,一次线程切换的开销是多少?准确的测试需要很多细节的把控,这里引用文章 Measuring context switching and memory overheads for Linux threads 的结论:
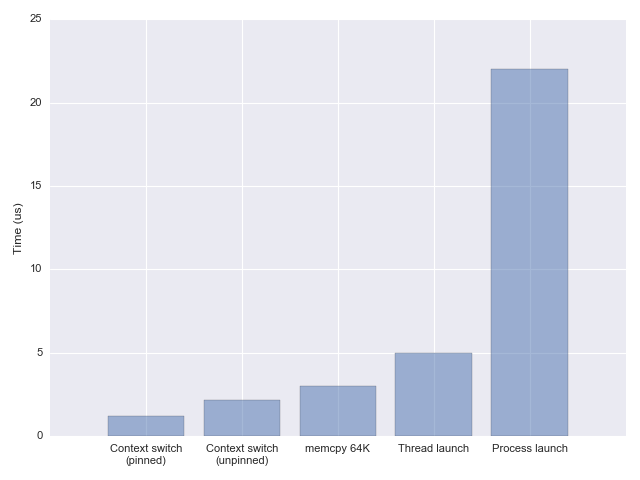
换言之,操作系统层面,一次线程切换大概需要 1~2us。日常情景下也是可以忽略的。
(如果想观察线程切换的频率,可以通过 vmstat 查看系统全局的切换情况,或用
pidstat -wt -p <pid> 查看某个进程的所有线程的切换情况)
开销之外
要注意的是,性能测试程序往往太片面,无法准确反映所有情况下的开销,所以正确看待上面结果的方式是:对开销的数量级有概念,不要过分迷信数字本身。实际编码时要以程序本身的性能测试结果为准。
同时我们也看到,绝大多数情况下,线程创建的开销、线程的内存占用及线程切换等开销都不太会成为瓶颈。因此虽然“线程池”技术本身的确能减少一些开销,但在我看来这并不能成为使用线程池的主要理由。
如果我们仔细挖掘,会发现我们使用线程执行任务,初衷是要并行执行任务,但是如果任务多了,我们其实有一些衍生的管理、编排的需求,例如:
- 顺序管理。任务按照什么顺序执行?(FIFO、LIFO、优先级)?
- 资源管理。同时有多少任务能并发执行?允许有多少任务等待?
- 错误处理。如果负载过多,需要取消任务,应该选哪个?如何通知该任务?
- 生命周期管理。如何在线程开始或结束时做一些操作?
上面列举的只是能想到的部分需求。其实推而广之,通常开始时我们只关注“任务”本身,但量变引起质变,数量多了,相应的会衍生出许多的管理、编排的需求。我们看到 Hadoop/Spark 会有资源管理、任务队列、错误记录等管理需求;微服务多了,我们也会需要像 Kubernetes 这样的容器编排工具做相应的管理。
在 Java 并发中,答案是“线程池”,即使无关乎开销,它也是必需品。
小结
本节中,我们对线程的一些开销做了量化:
- 创建、启动线程,约
70~80us - 内存占用,由于虚拟内存的机制,会按需占用物理内存,实验中看到初始占用
10~20K。 - 线程切换,引用了其它文章的数据,每次约
1~2us
再次强调这些具体的数字只做参考,关注数量级即可,实际要以程序的性能测试为准。
结论是,绝大多数情况下,这些开销都是微乎其微的,在性能测试前是不应该考虑的因素,也不应该是我们使用“线程池”的理由。使用线程池,更应该看重的是它的管理、编排的能力。这也是并发任务的量变引起的质变需求。