最近学了一些 Java GC 的知识,按自己的理解整理了一些 GC 算法遇到的问题和解决的思路。
免责声明:以下所有内容都是个人理解,可能与事实不符。
标记:三色算法
垃圾回收,需要先找出什么是垃圾,之后才能谈回收问题,一些方法
- 没有垃圾:认为所有对象都是存活的
- Reference Counting(引用计数):每个对象/资源设置一个引用计数,有新的引用则计数加一,引用释放后计数减一,所有引用都释放后则认为该对象是垃圾
- Tracing(跟踪):遍历对象的引用关系,过程中不可达的对象即为垃圾
引用计数在 C++ 和 Rust 之类的语言中比较常用,Java 中用的是 Tracing 的方式,遍历对象间的引用。那么从哪开始遍历呢?这些遍历的起始点称为 GC Root,在 Java 中有这么一些:
- 线程运行栈上的所有引用,例如方法的参数,创建的临时变量等等
- 系统加载的一些的类,比如说
java.util.*里的类 - JNI handles
- …
上面的 GC Roots 没列全,非专业做 GC 的话其实也没必要掌握。关键需要了解 GC Root 代表的就是我们“确定”还在用的引用,比如方法里创建了一个 HashMap,方法还返回前都“确定”还会用到,就认为是 Root(这里说得不准确,可能 new 出的对象就没人用,但从算法角度还是认为它是 Root)。
有了 GC Root,要如何扫描呢?Java 里用的是三色算法。三色算法是一个“逻辑算法”,本质上就是是树/森林的遍历,但为了方便描述和讨论,把遍历过程中的节点细化成三个状态:
- Black: 对象可达,且对象的所有引用都已经扫描了(“扫描”在可以理解成遍历过了或加入了待遍历的队列)
- Gray: 对象可达,但对象的引用还没有扫描过(因此 Gray 对象可理解成在搜索队列里的元素)
- White: 不可达对象或还没有扫描过的对象
每次迭代都会将 Grey 引用的 White 对象标成 Grey,并将 Grey 对象标记成 Black,直到没有 Grey 对象为止。标记之后一个对象最终只会是 Black 或者 White,其中所有可达的对象最终都会是 Black,如下例:

这里并没的说明 Grey 对象的遍历顺序,所以实际上实现成宽搜或深搜都是可以的。
回收:Sweep vs Compact vs Copy
上节说考虑的是“什么是垃圾”的问题,标识出了垃圾对象,下一步是如何“回收”。通常有 Sweep/Compact/Copy 三种处理方式,直观上理解是这样的:

- Sweep 指的是把垃圾清除了,但它不会移动活动对象,不过久了以后内存容易碎片化
- Compact 除了丢弃垃圾对象外,还会移动活动对象,紧凑地放到一个新的地方,能解决碎片化问题,但可能需要先计算目标地址,修正指针再移动对象,速度较慢。
- Copy 本质上和 Compact 是一样的,不过它的一些计算最会更少。但通常需要保留了一半的内存,移动时直接移动到另一半,空间开销会更大。
三种方法有各自的优势,需要使用方自己做权衡。这里引用 R 大的帖子 总结如下:
| Mark-Sweep | Mark-Compact | Mark-Copy | |
|---|---|---|---|
| 速度 | 中等 | 最慢 | 最快 |
| 空间开销 | 少(但有碎片) | 少(无碎片) | 通常需要活动对象的 2 倍(无碎片) |
| 移动对象? | 否 | 是 | 是 |
这几种方法都有使用。如 CMS 最后的 S 代表的就是 Sweep;传统的 Serial GC 和 Parallel GC,包括新的 G1、Shenandoah、ZGC 都可以理解成是 Compact;而 Serial, Parallel, CMS 的 Young GC 都用的是 Copy。
分代假设
如果接触过 GC,会知道 GC 最让人头疼的是 Stop-the-World 停顿,GC 算法的一些阶段会把用户线程的执行完全暂定,造成不可预期的停顿。我们希望这个时间尽可能短甚至完全去除。GC 的“效率”跟多方面因素有关,比如活动对象(active object)越多,Marking 需要遍历的节点越多,越耗时;比如内存越大,Sweep 清理垃圾时需要遍历的区域越大,耗时越长;等等。于是人们在想怎么“偷懒”来提升效率。
分代假设就是这样一个发现/假设:
- 多数对象一般创建不久后就被废弃了/死了
- 一段时间后还在使用/活着的对象,通常还会继续存在/活(非常)长的时间
从对象存活时间和对象数量的视角来看,分代假设就是这样的(原图):
{kind=link}

当然这个假设不一定符合实际,比如 LRU 缓存,越老的对象越可能被淘汰。不过多数应用还是符合这个假设的。于是如果将对象按时间分成年轻代和老年代,我们就可以偷懒了:
- 年轻代的对象死得快,因此通常回收年轻代收益更高,于是可以更频繁回收年轻代,少最回收老年代
- 回收年轻代时的标记阶段可以简化。例如存在 Old -> Young 的引用,正确的做法是用三色算法判断 Old 里的对象是死是活,再来判断 Young 对象的死活,但在分代假设下,可以偷懒地认为 Old 的对象就是活的,这样可以减少 Mark 的时间且不太影响回收的效果。
于是在分代假设下,传统的 GC 流程变成了这样(原图):
{kind=link}
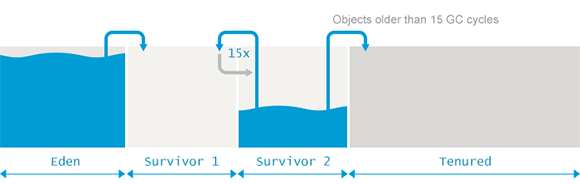
新对象从 Eden 区分配,Young GC 时存活的进 Survivor 区,Survivor 区有两个,相互做 Copy 操作。在 Survivor 区存活了 15 次 GC 的,就移动到 Old/Tenured 区。Young GC 时会忽略 Tenured 区。
并发提速
前面提到了 GC 最让人头疼的是 STW 停顿,分代策略让我们频繁做 Young GC,少量做 Full GC,但真的做 Full GC 时停顿时间还是非常大,于是人们想到了并发。CMS 中的 CM 指的是 Concurrent Mark 即是“并发标记”。而 Shenandoah GC 和 ZGC 又实现了“回收”的并发。
开始前要注意的是“并发”和“并行”在 GC 里的概念是不一样的,可以这么去区分:
- 并行:起多个线程一起处理,但对应用线程依旧是 STW 的
- 并发:GC 线程处理 GC 任务的同时,应用线程依旧可以运行
如早期的 Parallel GC 本质上就是“并行”而不是“并发”,GC 过程还是 STW 的。虽然仅一字之差,“并发”会带来非常多的问题,新的 GC 算法也用了许多解决方案,但这些方案都是有代价的。
并发标记
前面提到 Java 里会用三色算法来遍历堆中的引用关系,算法假设引用关系在遍历期间不变,如果变化了会怎么样呢?主要有两个场景:新增对象和引用修改。
第一个问题是新增对象:在标记期间新增的对象通过旧的 GC Roots 可能不可达,标记结束后可能还是 White,会被认为是垃圾而被错误释放。
第二个问题是:标记期间应用线程修改引用会影响正确性。
其中一些修改不会造成错误,只是会影响回收效率。如断开 Black1 -> Black2 引用, Black2 最终应该被释放,但不释放 Black2 不会造成程序错误。但如果修改同时满足下面两个条件则会影响正确性:
- 应用线程增加 Black -> White 的引用,这意味着这个 White 对象标记结束后是被引用的,预期是 Black
- 应用线程断开了 Grey -> White 的(直接或间接)引用,这意味着原本 White 对象能通过该 Grey 对象被遍历到,但现在却遍历不到了
条件一和条件二的共同结果是,标记过程会遗漏这个 White 对象,因为通过 Grey 对象不可达,且 Black 对象不会被二次扫描。于是 GC 结束后它会被释放,但它同时还被 Black 对象引用着,程序会出错。
并发标记算法如何解决这两个问题?
Incremental Update
Incremental update 的想法是破坏条件一。标记期间记录增加的每个 Black -> White 引用中的 White 对象,把它标记为 Grey。对于标记期间新增的对象,则需要在标记结束前重新扫描一次 GC Roots 做 Marking。
在实现上,就需要去“监听” Black -> White 引用的创建。以 CMS 为例:
- CMS 会在程序的引用赋值语句(如
obj.foo = bar)后,插入一段代码(称为 barrier,因为是在赋值结束后的 barrier,所以称为 post write barrier),这段代码会记录 foo -> bar 的引用。 - CMS 会在内存中开辟一块区域,称为 Card Table,用来记录 foo -> bar 的引用
在标记过程中新增的 Black -> White 的引用,都可以在 Card Table 中找到。于是要保证标记的正确性,只需要在标记结束前从 Card Table 中找到 foo -> bar 的引用,再用三色算法遍历一下 bar 及其引用即可。当然还需要再重新扫描 GC Roots 处理新增的对象。
实现细节上,Card Table 里并不会像 HashMap 一样记录一个 A -> B 的映射,这样存储访问的效率都很低。Card Table 是一个 bitmap,先将内存按 512B 分成一个个区域,称为 Card,每个 Card 对应 bitmap 里的一位。bitmap 置 1 代表对应 Card 中包含需要重新扫描的对象。在标记结束前找到为 dirty 的 Card,重新扫描其中的(所有)对象及其引用。

Snapshot At The Beginning
Snapshot At The Beginning(SATB) 的想法则是破坏条件二,在标记开始之前做快照,快照之后新增的对象都不处理,认为是 Black;当要删除旧的引用(换句话说,在新的赋值 obj.foo = bar 生效之前),记录旧的引用,这样在标记结束前再扫描这些旧的引用即可,这样原先的 Grey -> White 的引用虽然断开了,但 White 对象依旧可以扫到。以 G1 为例:
- 在每个 Region 会有 TAMS(top at marking start) 指针,标记开始时设置为 Top 的值,区域内新增对象后 Top 指针增长,可以认为 [TAMS, Top] 之间的对象都是新对象,都置为 Black 即可
- 在赋值语句之前加入 barrier,例如
obj.foo = bar可以拆成barrier(obj.foo); obj.foo = bar,barrier 会对赋值前的指针做记录。因为是在写指针之前做的操作,因此也叫 pre write barrier - G1 使用了和 Card Table 类似的结构叫 Remember Set(RSet),用来记录 pre write barrier 传递的指针。
最终的操作与 Incremental Update 类似,在标记结束前,重新扫描 RSet 里记录的指针,也会有额外的操作把 [TAMS, Top] 之间的对象标记成 Black。
实现细节上,G1 将内存分成了多个 Region。每个 Region 有自己的一个 RSet,这点与 Card Table 不同,它是全局的。RSet 的结构如下:

- 每个 Region 有自己的 RSet
- RSet 里记录的的:指向当前 Region 的有 Region xx Card yy, …
- 如果要回收 Region3,只需要扫描 Region3 对应的 Reset 里的指针(即 R1C4 和 R2C2)
当然,RSet 的具体实现和上图不太一样,如一般用 HashMap 来存储;但如果 region 里的 card 数过多就会退化成 bitmap;引用的 region 过多,则 region 也会用 bitmap 来存储。细节上也有很多优化,比如 barrier 的更新是先记录到一个 Thread Local 的队列上,异步更新到 RSet 中的。
Concurrent Copy/Compact
不管是在 CMS 和 G1 里,并发的内容主要还是以 Marking 为主,Copy/Compact 还是 STW 的。如 CMS 的 Young GC Copy,G1 的 Evacuation Compact,都是 STW 的。为了追求接近硬实时的效果,Shenandoah GC 和 ZGC 都尝试将“回收”阶段并发化,减少 Copy/Compact 的 STW 停顿时间。而正如并发标记里会需要处理新对象和并发修改的问题,并发 Copy/Compact 也会遇到不少问题。
并发修改问题
Copy/Compact 的过程,需要先将对象复制到新的位置,再修改所有该对象的引用,指向新的地址。在 STW 的方案下,过程如下(摘自 https://shipilev.net/talks/javazone-Sep2018-shenandoah.pdf ):

- 先复制对象
- 将复制后对象的指针存放在原对象的 Header 中(复用空间)
- 遍历堆上的指针,将指针的值置为对象的 Header 中存储的指针(
*ref = **ref) - 所有指针更新完毕,释放旧的对象
但允许并发时,会出现不同线程对不同副本做读写的问题,此时应该保留哪个副本?

并发回收算法的核心也就在于怎么解决 Copy 期间多线程对两个副本的同步。下面会介绍 Shenadoah GC 和 ZGC 的做法,它们都会用到 load barrier 来修正并发情况下应用线程的读操作。
Brooks Pointer
Shenandoah GC 对这个问题的解法是:为每个对象都增加一个 Forwarding 指针,在 Copy/Compact 过程中,通过 CAS 来更新这个指针指向新的副本,期间指向该对象的指针的读写,都要经过 Forwarding 找到正确的对象,如下图所示。

这个方案的有效性本身并不难理解。技术上,这个方案需要拦截所有的对读写操作,让它通过 FwdPtr 完成。Shenandoah GC 通过 Write Barrier + Load Barrier 来完成。
一个小细节:在执行 Write 操作时,Write Barrier 如果发现当前处于并发 Copy 阶段,但对象还没有被 Copy,则 Write Barrier 会执行 Copy 操作,否则写到旧的副本里也没有意义。但读操作时并不会主动做 Copy 的动作。
这个算法的难点在于实现和优化。Shenandoah 中做了许多额外的处理:例如在更多地方增加 barrier,比如 == 、compareAndSwap等操作;例如去除对 NULL 检查的 Barrier,把 barrier 放在循环外来提高性能。
另外 Brooks Pointer 中的 Brooks 是人名,Rodney A. Brooks 在 1984 年为 Lisp 发明的。
ZGC Relocation
一个 A->B 的引用有两个参与者,引用方 A 和被引用方 B。Shenandoah 是在被引用方 B 中增加 Forwarding Pointer 来屏蔽底层的 Copy 的动作。而 ZGC 则是在引用方 A 处动手,具体有这么几个机制:
- 在指针中挑几个 bit 来做标记,其中
remapped位代表的当前指针是否指向 Copy 后的地址 - Copy/Compact 的过程中,ZGC 会为 Region 创建 forwarding table,用于保存新旧对象地址的映射
- ZGC (只)会用 Read Barrier,在访问指针时,如果当前指针的
remapped位为0,代表指针未更新,会查找 forwarding table 的值来更新当前指针,之后再进行访问 - 如果在 Copy/Compact 的过程中指针并没有被访问,则在下次 marking 时会由 GC Thread 来更新指针。
如果画成图,大概是这样:

相比于 Brooks Pointer,这个算法会更受限,比如无法支持 32 位的机器,不能开启指针压缩等等。
那么代价呢?
先假设这样一个情形,如果我们看 GC 的日志,记录 GC 开始结束,(虚构)画出下面这张图:

图中 2 的位置,我们发现应用程序的 TPS 和响应时间都变差了,但看了下 GC 的日志发现每次 GC 的停顿时间都很短,可能会觉得 GC 没有问题。但如果仔细观察,会发现 GC 变得频繁了,而 GC 是消耗 CPU 时间的,更频繁的 GC 意味着应用线程能用的时间也更少了,因此会造成 TPS 和响应时间变差的情况。
除了 GC 带来的停顿之外,要意识到 GC 是有代价的:
- GC 的一些内部结构需要占用额外的内存,如 Card Table, RSet, Forwarding Pointer, Forwarding Table, etc.
- Shenadoah, ZGC 这种重度 barrier 使用者,不发生 GC 时也会有额外的 CPU 占用(比如 Shenandoah 大概 20%,ZGC 大概 15%,视具体程序有变化),这也是低延时 GC 的额外代价
- 另外在真正执行 GC 时,GC 线程也会占用 CPU
一般 GC 算法保证的停顿的时间越短,则消耗的 CPU 越大,换言之吞吐越小。没有通用的最优的 GC 算法,根据应用程序的不同和愿意付出的代价来选择 GC 算法吧。
小结
文章中粗浅地讨论了 Java GC 算法中的几个方面:
- 标记用的三色算法,它是树遍历的一个抽象描述,有助于理解和讨论
- 回收用的 Sweep, Compact, Copy 三种策略和各自的优缺点
- 分代假设:越年轻的对象越可能死亡,越老的对象越可能活得久。GC 算法可以通过分代来提高性能
- 为了减少停顿时间,GC 算法引入了并发标记和并发回收,而它们本身又引入了新的问题
- 并发标记的问题介绍了 Incremental Update 和 Snapshot at The Beginning,分别打破引发问题的两个必要条件的一个
- 并发回收问题介绍了 Shenandoah GC 使用的 Brooks Pointer 和 ZGC 使用的策略。
- 最后简单讨论了 GC 算法对应用程序本身的影响。
参考
- [讨论] 并发垃圾收集器(CMS)为什么没有采用标记-整理算法来实现? 收集的几种算法对比
- [讨论] [HotSpot VM] 关于incremental update与SATB的一点理解 Incremental Update 和 SATB 的讨论
- Shenandoah: Theory and Practice 介绍了 Brooks Pointer 及 Shenandoah 中的许多 Barrier 优化。
- The Z Garbage Collector: Low Latency GC for OpenJDK PPT,里面介绍 ZGC Relocation 的图很好
- G1 Garbage Collector Details and Tuning by Simone Bordet 关于 G1 的细节和注意事项说得非常好
- GC Algorithms: Implementations Plumbr 的文章,一定要仔细反复读,描述了各种 GC 的实现(暂不包括 Shenandoah 和 ZGC)
- G1 Garbage Collector Paper G1 的论文,里面对 G1 的 TAMS 的工作机制描述得很清楚
- A FIRST LOOK INTO ZGC ZGC 很好的入门文章
- Shenandoah GC Part I: The Garbage Collector That Could 对 Shenandoah 的技术要点和 BenchMark 的说明通俗易懂,配合 Talk 观看效果更佳